82. 删除排序链表中的重复元素 II
题目
给定一个已排序的链表的头 head , 删除原始链表中所有重复数字的节点,只留下不同的数字 。返回 已排序的链表 。
示例 1:
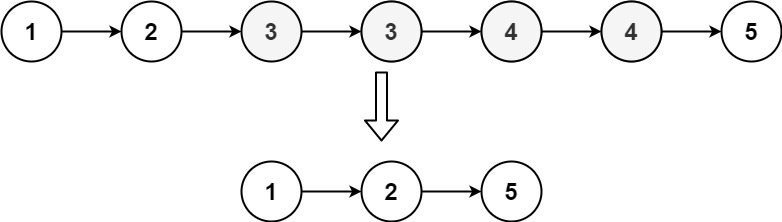
输入:head = [1,2,3,3,4,4,5]
输出:[1,2,5]示例 2:
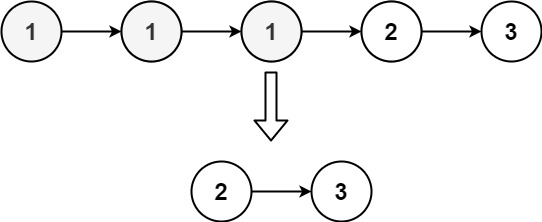
输入:head = [1,1,1,2,3]
输出:[2,3]提示:
- 链表中节点数目在范围
[0, 300]内 -100 <= Node.val <= 100- 题目数据保证链表已经按升序 排列
解答
思路
这道题和 83 不一样,因为是删除所有重复的结点,因此可能会删除头节点,于是需要 dummy。算法为:
- 看
cur.next.val == cur.next.next.val是否相同 - 如果相同,说明至少有两个重复的结点,它们的值为
cur.next.val = val - 进入循环,不断判断
cur.next的值是否为val,如果是,删除它
复杂度:看似两重循环,实际上每次循环 cur = cur.next,或者删除掉了一个结点,因此只会遍历一次。
- 时间复杂度为
- 空间复杂度为
代码
Python 代码
python
class Solution:
def deleteDuplicates(self, head: Optional[ListNode]) -> Optional[ListNode]:
dummy = ListNode(next=head)
cur = dummy
while cur.next and cur.next.next:
val = cur.next.val
if cur.next.next.val == val: # 至少两个为 val,删除所有 val
while cur.next and cur.next.val == val:
cur.next = cur.next.next
else:
cur = cur.next
return dummy.next