哈希表
- 存储结构
- 开放寻址法
- 拉链法
- 字符串哈希
哈希表的作用:把一个较大的空间映射到较小的空间
维护集合,支持以下几种操作:
- 往集合中插入一个整数
- 询问某个整数是否在集合中
- 操作数:
,数据范围
哈希函数:
哈希冲突
显然,对于最简单的哈希函数而言,
哈希表和离散化的区别在于:离散化需要 保序,是一种特殊的哈希方式。
拉链法
- 开一个
大小的数组 - 每次当我们准备存储数据时:
- 找到数据对应的哈希结果为下标的数组位置
- 在该位置放一个链表,依次往链表下方放数
- 例如数组大小为
,那么 13->23->33->...
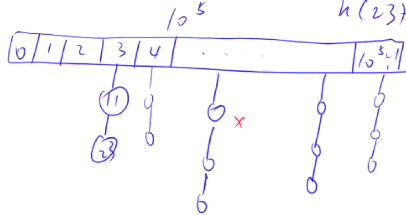
哈希算法的期望时间复杂度是
在算法题中一般不涉及删除哈希表中的元素操作,只有 添加和查找 两种操作。如果要实现删除,一般不会真的删除,而是另开一个新的数组,打上 bool 标记,判断该元素是否已经被删除(因为删除链表中的节点太慢了)。
一般来说数组的长度取一个质数,并且要离 2 的整次幂尽可能远,这样冲突概率最小
核心代码:
void insert(int x) {
int k = (x % N + N) % N;
e[idx] = x;
ne[idx] = h[k];
h[k] = idx;
idx ++;
}
bool find(int x) {
int k = (x % N + N) % N;
for (int i = h[k]; i != -1; i = ne[i]) {
if (e[i] == x) {
return true;
}
}
return false;
}注意在 C++ 中负数取模依然是负数,例如 -10 % 3 = -1;,为了让 x 取模得到的 k 是正数,则需要 int k = (x % N + N) % N; 注意,这里不能直接 int k = (x + N) % N;,因为 x 的范围是 % N 是为将数控制在
开放寻址法
只开一个一维数组,但是注意数组的长度需要开到题目要求的 2~3 倍,此时冲突概率较低。
- 添加一个数,找到它对应的哈希下标
k - 如果没有被占用,直接填入
- 如果被占用,遍历它后面的位置,直到找到第一个空的位置插入
- 查找同理
- 删除可以看作是查找的一种
核心代码:
int find(int x) {
int k = (x % N + N) % N;
while (h[k] != INF && h[k] != x) {
k ++;
if (k == N) {
k = 0;
}
}
return k;
}这里 INF = 0x3f3f3f3f = 1061109567 > 1e9。
字符串前缀哈希
有很多字符串问题都可以用字符串前缀哈希来完成,不一定要写 KMP。
对于某个字符串 str = "ABCABCDEXYZ 而言:
- 对于字符串前缀,考虑一个
进制数 - hash 函数为字符编号对应的底数组成的
进制数 h[0] = 0h[1]为"A"字符串的 hash 值,也就是h[2]为"AB"字符串的 hash 值,也就是h[3]为"ABC"字符串的 hash 值,也就是- ...
- 由于进制数和前缀的一一对应关系,因此不会出现冲突
- 转化后的数字可能会非常大,最后需要取模
Q,这样就是映射到0 ~ Q-1的一个十进制数了
注意,我们的 "A" 是要从 1 开始而不能从 0 开始,如果从 0 开始,那么 "AA" 对应的就是 00 = 0,二者发生冲突,矛盾!
这里我们假设我们的人品足够好,不会产生映射后的冲突。一般取
字符串前缀哈希的作用:类似前缀和的思想,可以计算出所有子串的哈希值:想要求出 [l, r] 子串的哈希值:
- 首先获得
h[l-1], h[r]两个值h[i] = h[i - 1] * p + str[i]h[r] = str[0] * (p^{r-1}) + ... + str[r-1] * p^0h[l-1] = str[0] * (p^{l-2}) + ... + str[l-2] * p^0- 二者之间
str[i]差的倍数是p^{r-l+1}
- 最终公式就是
h[r] - h[l-1] * (p^{r-l+1}) - 用
unsigned long long来存储h即可,溢出等于取模
例如:"ABCABCDEXYZ" 中的 "BCA" 就是 "BCA" 是 "BCA" 这个三个字符的字符串中它仍然也是
因此字符串哈希可以用来判断 字符串匹配!时间复杂度为
核心代码:
ULL get(int l, int r) {
return h[r] - h[l - 1] * p[r - l + 1];
}
// ...
p[0] = 1;
for (int i = 1; i <= n; i ++) {
p[i] = p[i - 1] * P;
h[i] = h[i - 1] * P + str[i];
}其中:
h[i]是字符串前缀哈希p[i]表示p^i
KMP 可以用来求循环节,字符串哈希不如。其他所有字符串问题它都比 KMP 要好。