第五章 学习理论
回顾一下机器学习的基本框架:
- 任务是求出未知的目标函数:
- 给出一组训练数据
- 选定一个假设空间
:一般由先验知识给出 - 通过某个学习算法
:一般是经验风险最小化 Empirical Risk Minimization,ERM 方法 - 最后找到关于该组训练数据的假设函数
这其中有几个理论上的问题:
- 学习是否是可行的?什么条件下是可学习的?
- 是否可以高效地进行学习?如何对学习算法进行理论分析?
统计学习
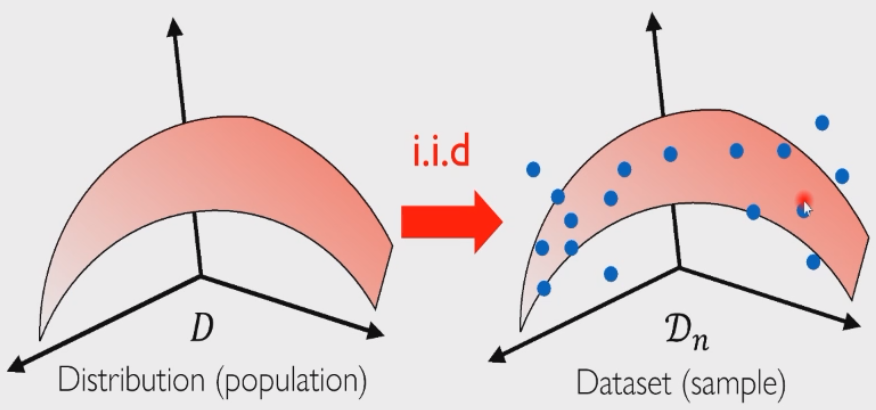
我们这一代机器学习也被称为统计学习,从统计的视角来看,我们一般会有一些基本假设:
- 数据都是由一个潜在分布
采样得到的 - 训练、测试样本都是由分布
独立同分布采样生成的
那么这
独立同分布
首先我们介绍所谓独立同分布 Independent and Identically Distributed,i.i.d 假设:
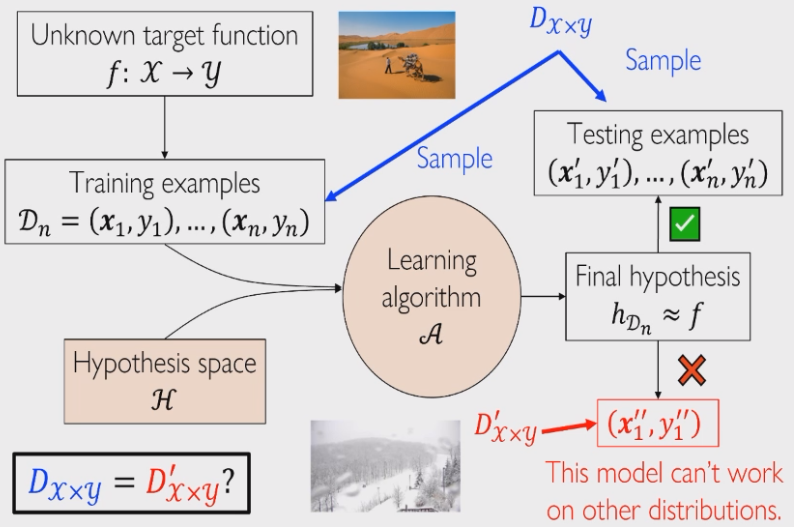
- 首先从潜在分布
中采样得到训练数据 - 然后训练模型,得到我们的假设函数
- 之后再从潜在分布
中采样另外一组测试数据 - 将模型作用到测试数据上,研究模型的预测值和真实值之间的差距
这里面有一个隐藏的假设就是:测试样本和训练样本都是从潜在分布
泛化
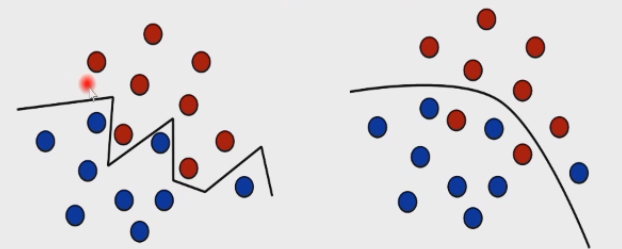
我们知道,学习 learning 和拟合 fitting 不同,例如左图就是一个很好的拟合,但是它不是一个好的学习;右图就是一个很好的学习,但有些点没有完全拟合。二者的区别就在于泛化 generalization 能力。如果一个学习模型在由分布
这代表了我们的一个偏好:正确的决策面往往不会过于复杂。就好比麦克斯韦方程组,真理往往都是简单的。同样,过于复杂的模型往往会被噪声所干扰,同时也不好解释。
泛化不是记忆,人类学习知识的过程也是泛化的过程,“举一反三”和“触类旁通”就是泛化。机器学习的终极目标就是追求更好的泛化性。现实世界往往需要做一些权衡 trade-off,例如样本大小和模型复杂性之间,以尽量获得好的效果。
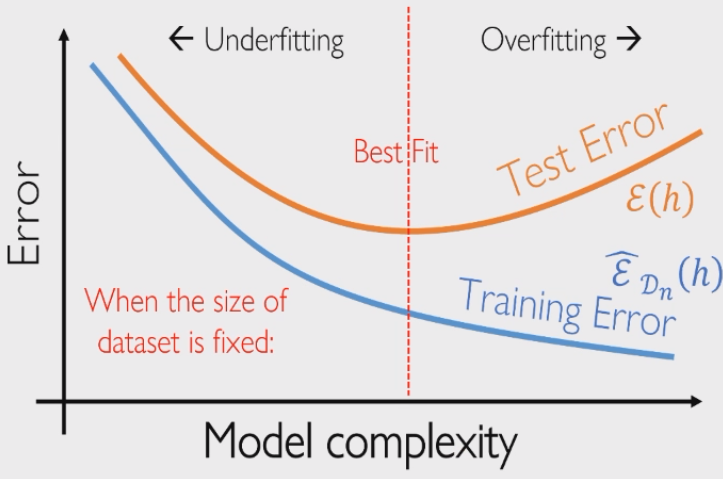
期望误差和经验误差
期望误差 expected error 描述的是:某个假设模型
表面上是随机采样了一条样本
经验误差/训练误差 empirical/training error 描述的是:某个假设模型
期望误差和测试误差 test error 之间是否一样?期望误差是在分布
我们要在测试集上计算模型的测试误差,而如果测试集是一个足够大的随机分布的集合,那么测试误差可以很好地反映期望误差——大数定律。这就引出一个问题:测试集和训练集都要足够大,因此这里也需要做权衡。
经验误差是期望误差的无偏估计,需要对
如果我们知道这个数据集是由
即取概率更大的标签作为输出值,这也叫贝叶斯决策准则,此时犯的错误就是最小的。如果这个时候还是犯错了,那么就把这种不可约减的错误率称为贝叶斯错误率:
偏差方差分解
定理:对于任何一个样本
:条件方差:随机变量 在 下的方差 :在数据集 上学到一个模型
首先这个定理是在回归问题上推导的,因此损失函数采用 L2 loss,它的微积分性质是最好的。我们记从样本集
由于模型
接下来,我们求这样一个条件期望:
上式最后一项利用期望的独立性可以写成:
因此可以写为:
红色项就是标签噪音,也就是贝叶斯错误率
蓝色项可以写为,加减了
由于:
因此原式最后只剩前面两项:
- 偏差:估计值
的期望与真实值 的差距 - 方差:将
看作随机变量,因此这就是 的方差/离散度
如果对于不同的训练集,
因此我们能否找到一个模型,使得上述三项都很小,这样模型的期望误差就很小。遗憾的是,这是不能成立的:
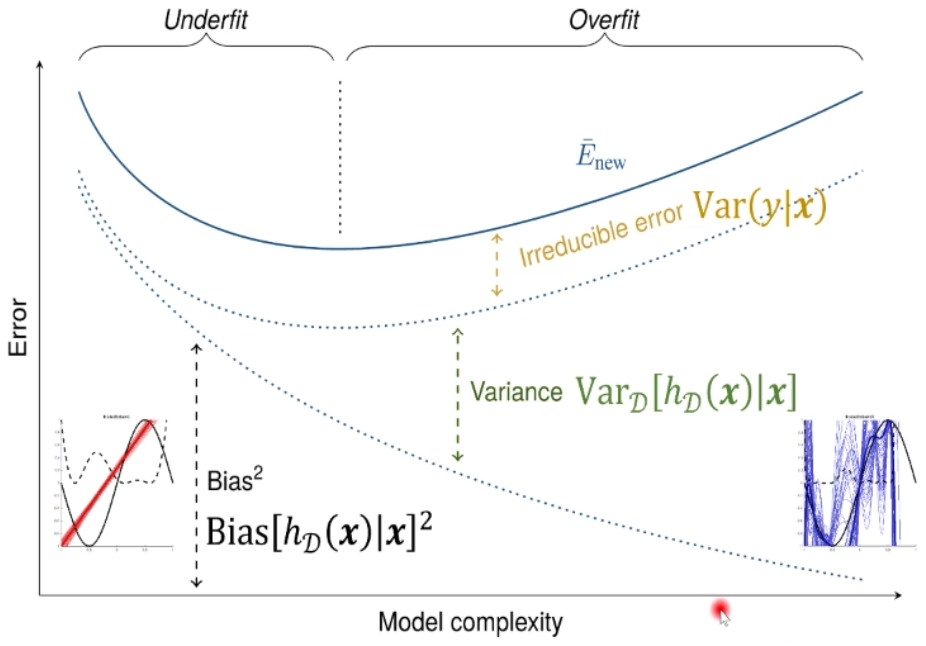
- 贝叶斯错误率是不可约减的 irreducible
- 模型简单时:参数不容易变化,方差小;容易欠拟合,偏差大
- 模型复杂时:参数易发生变化,方差大;拟合较准确,偏差小
偏差方差权衡定理告诉我们:方差和偏差不能同时减小。例如深度学习模型就是用一个非常复杂的模型使得偏差非常小,同时为了避免方差过大,它需要大量的数据用于训练。或者可以使用多个模型做投票/结果求平均值,取均值也会降低方差。
概率近似正确
近似误差与估计误差
偏差方差是在回归问题中推导出来的,而近似误差和估计误差适用于所有机器学习问题:
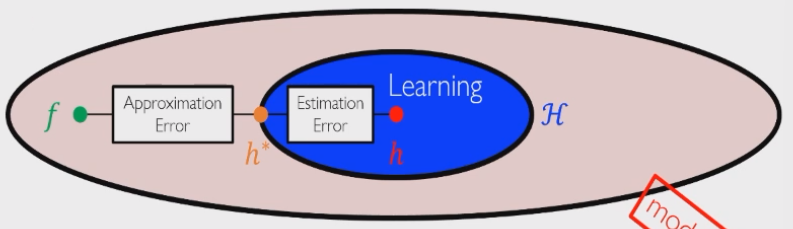
现实中我们只会取到蓝色区域作为假设空间,假设空间中自然存在一个最优的函数
- 近似误差:表示假设空间的选取优劣程度,是一个确定量
- 估计误差:表示假设函数的选取优劣程度,我们可以给出估计误差的上界
泛化界
估计误差也就是期望误差
如果这个式子尽量小,说明随着随机变量
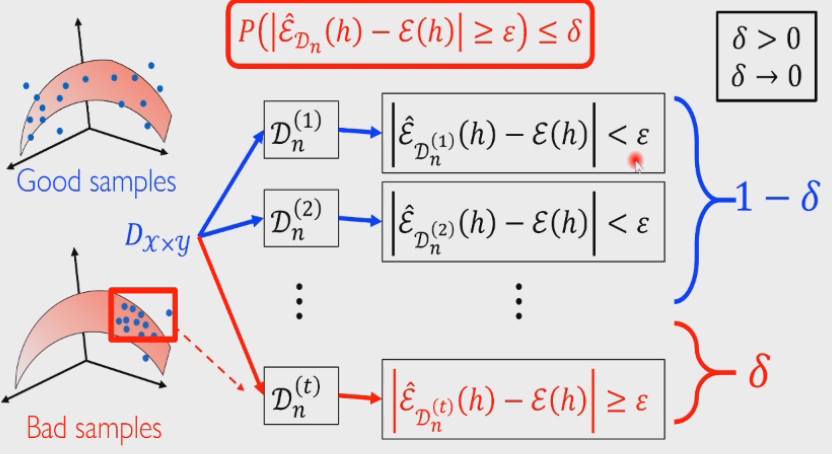
但显然,由于采样具有随机性,我们也许会采样到有偏的一个样本,而且在机器学习中收集数据是很容易发生这种情况的,由此衍生出数据科学 data science 这一门学科。因此我们只能做妥协:希望这个随机变量尽可能满足比较小的性质,也就是随机变量比较大是一个小概率事件:
如果某个学习模型满足:经验误差和期望误差之差大于某个给定常数
PAC 可学习性理论
PAC 学习:概率近似正确学习 Probably Approximately Correct Learning,它是整个机器学习得以实现的基础工作。
一个假设空间
到此为止才会发现,概率近似正确是统计学习的上界了。PAC 可学习性理论由图灵奖获得者 Leslie Variant 由 1984 年在《A Theory of the Learnable》中提出。
一般来说,样本条数
概率工具
基本性质
并集的上界 Union bound:
概率的反函数:如果有
证明:记
既然
琴生不等式 Jensen's inequality:如果
这就是凸函数的定义。
集中不等式
回顾我们在 PAC 学习中的目标(这个似乎和 Variant 的理论不一样?那个是两个期望误差之差,这个是经验误差和期望误差之差,不急,先卖个关子):
改写上述不等式:即有至少
这个就是求出了期望误差的上界。注意到期望误差是经验误差的期望,即:
概率中几乎所有的不等式都是集中不等式:大数定律、中心极限定理等等,集中不等式能够控制住随机变量的范围,注意到我们没有对随机变量
马尔可夫不等式
Markov's Inequality:对于任意一个非负随机变量
证明:利用期望的定义,
这里要求
切比雪夫不等式
Chebyshev's Inequality:如果
第一个不等式是利用了事件的包含关系,由于
切比雪夫不等式就是一个集中不等式:某个随机变量以它均值为核心的事件是一个大概率事件,偏离核心的是一个小概率事件。
弱大数定律
Weak Law of Large Numbers:设
因此对于任意的
证明:由于
利用切比雪夫不等式,有:
大数定律在机器学习中基本没有作用,因为
有限样本界
切尔诺夫限
Chernoff Bound:在马尔可夫不等式中,令函数不是二次函数,而是指数函数
指数函数的好处就是乘法可以转化为指数相加,适合做极大似然估计。同时我们令
如果
这里运用了独立事件期望的独立性,即
霍夫丁引理
Hoeffding's Lemma:如果
证明:利用指数函数是凸函数的性质,由琴生不等式,函数值小于端点弦上一点:
两边对于随机变量
因此我们只需要证明:
证明:对
令:
原式改写为:
求导(已验算):
注意到:
霍夫丁不等式
Hoeffding's Inequality:对于
可以看到指数项是一个关于
代入上式就求到了最紧的一个限:
- 第一个不等式:切尔诺夫限
- 第二个不等式:霍夫丁引理
- 第三个不等式:二次函数的最小值
最后,如果我们用
加起来写成绝对值的形式,就得到了最终的霍夫丁不等式,对于
麦克迪尔米德不等式
McDiarmid's Inequality:(霍夫丁不等式的推广版本)记
自变量发生了变化,但函数值的变化始终有上界
如果令函数
此时就可以得到霍夫丁不等式(即
麦克迪尔米德不等式就是有限样本情况下的集中不等式:它表示了任意一个随机变量
因此只有当
有限假设空间上的泛化界
单假设函数
有限假设空间 Finite Hypothesis Space:
如果令随机变量
我们可以控制住经验误差与期望误差的差!再用
回顾概率的反函数性质(右边是减函数),我们令:
因此反事件就有至少
这就是期望误差
多假设函数
无限假设空间上的泛化界
线性分类器的泛化界
采样的随机性导致的模型的随机性,因此模型的经验误差需要和期望误差之间不能差的太远。