第四章 支持向量机
支持向量机
支持向量机 Support Vector Machine。
首先,我们再重新思考一下如何二分类?对于高维空间中的样本点,要将它们分开来,一个几何视角就是:找到一个超平面,将它们分开。注意,超平面自然是一个线性模型,但是我们之前研究线性模型更多的是从统计观点来看的,现在我们就从几何视角入手。
我们不在用
- 分对了:
,即 - 分错了:
,即
标签值和样本之于超平面所处的位置是否一致:标签为正表示样本在超平面上半部分:
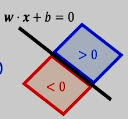
问题:怎样去选择最好的分类器/超平面?之前在统计的意义下已经解决了这个问题。现在我们从几何视角下回顾:
显然 4 号超平面是最好的,因为它离所有样本最远。计算点到超平面的距离!找一个最大间隔 margin 的超平面,它对于噪声数据的鲁棒性最强。那么如何确定带有最大间隔的超平面呢?首先要找到一个正例的上夹板和负例的下夹板,使得上夹板和下夹板之间的间隔达到最大,将其称之为 margin,居中的超平面就是我们要找的超平面。(最小间隔,最大间隔,平均间隔?)
间隔:距离两个类中最近的点之间的距离称为间隔:也被称为 最小间隔。
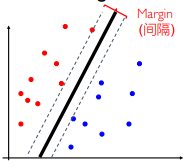
需求:
- 间隔尽量大
- 所有的点都分对
这里的 1 是一个 裕度。如果我们说
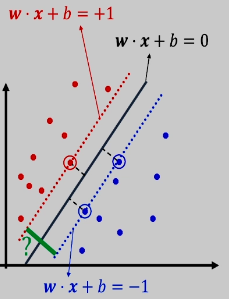
点到平面的距离公式
定理:设平面外的一点
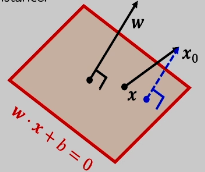
设超平面上有一点
Project 就是投影。我们再以二维向量来说明这个间隔:
首先,满足
但是问题就在于:找到了上夹板,那么下夹板就一定存在吗?不一定,举一个极端的例子来看:假设正例全部分布在
于是我们这里就又有了一个前提:这样的夹板是可以找到的。那么样本点中离分类面最近的点最近的所在只能是在上下夹板上,即
这里求的间隔不是到点的间隔,或者穿过点的直线的间隔,而就是到裕度为 1 的上下夹板之间的间隔。当然我们最后所求的最大值一定能够满足至少一个夹板上有数据点:
在我们实现了这个约束条件的时候,就说明我们创造了两个夹板,并不需要夹板上有没有数据点,我们所求的最大值也是夹板间的间隔最大值。例如只有两个点
任意给两个点都能找到恰好满足
这也被称为硬间隔支持向量机 High-margin SVM:
- 1/2 为了方便计算
不是凸函数,但是 是凸函数
这是一个 线性约束的二次优化问题。前面的都是线性可分的数据 —— 很强的假设。
线性不可分情况下的分类
线性不可分或者过拟合的情况:
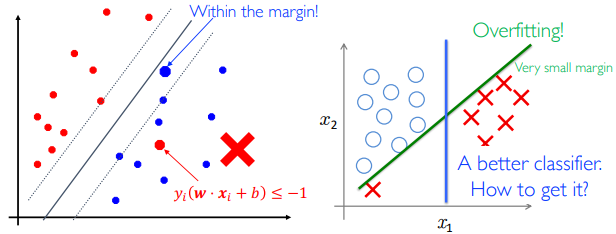
不能过分要求线性可分:允许一部分点在错误的那一边。但是在错误那一边点的数量不能多。因此:
我们称
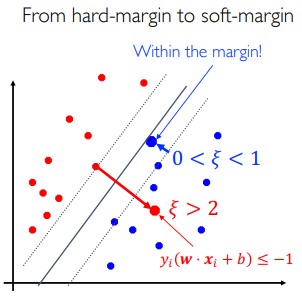
收益就是间隔可以更大了,是一种权衡犯错点数量和间隔大小的方法:将约束的和式放到目标函数上(软间隔支持向量机的目标函数):
对任何的
支持向量机无法做多分类任务:几何直观模型的天然局限,还会存在 Ambiguity 死角。
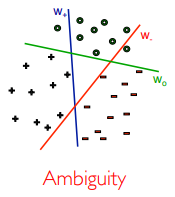
对于
支持向量机的重要性:
- 学科发展
- 引入的最大间隔思想
- 引入的核函数方法
默认的软件包将超参数
联合优化
将
超平面下本类的 score:
约束优化问题
凸优化
Convex Optimization:SVM 是一个线性约束的二次优化问题。高中数学中,一般都是固定一组变量就是求另外一组的最小值。
是一个凸集, 是一个凸函数 - 凸集
的定义: :两点连线在集合内 - 凸函数
的定义: :割线在弧的上方
如果:
,那么就是一个不带约束的优化问题,微积分求导即可 ,且是一个凸集合,那么这就是带约束的优化问题 Constrained Problem
等式约束
可以将约束写为如下形式:
首先,如果是无约束优化问题,那么最小值对应的就应该是
其次,我们考虑最优的点

上面一个条件是对于所有点成立的,下面一个条件只对于最优点成立。那么既然二者是平行关系,那么存在一个
其实就是关于
拉格朗日函数有两个变量,分别求导数:
对两个变量的导数都为 0 才是驻点。拉格朗日函数的驻点就是所求的最优点。
不等式约束
Inequality Constraints
如果最优解在区域内部,那么约束失效,求解关于

总结得到 KKT 条件(Karush-Kuhn-Tucker Conditions):对于拉格朗日函数:$ L(\boldsymbol{x}, \lambda)=f(\boldsymbol{x})+\lambda g(\boldsymbol{x}) $,它需要满足:
:Primal Feasibility 原问题的可行解区域 :Dual Feasibility 对偶可行解区域(新引入的变量 称为对偶变量) :Complementary Slackness 补充松弛变量(将内部解和边界解写在一起)
一般意义的拉格朗日函数
考虑如下的原问题:
优化问题的正规性条件:#TODO
为什么是加起来?因为都要满足导数互相平行的关系!得到推广的 KKT 条件,对于所有的
- Primal Feasibility:$ g_{j}(\boldsymbol{x}) \leq 0, h_{k}(\boldsymbol{x})=0 $
- Dual Feasibility:
- Complementary Slackness:
求导:
如果求到的三个驻点
原问题和对偶问题
根据拉格朗日函数引出的原问题和对偶问题,首先来看原问题:
那么它的拉格朗日对偶问题为:
什么是
原来的函数的自变量是
定理:如果对一个仿射函数(线性函数)的点点最小值是一个凹函数。https://web.stanford.edu/~boyd/cvxbook/bv_cvxbook.pdf,显然,拉格朗日函数是关于对偶变量的仿射函数。SVM 是一种带约束的优化问题,引入拉格朗日对偶问题的收益有限,因为 SVM 的约束很好。
如果原问题是凸问题,那么对偶问题和原问题的解相同;如果原问题不是凸问题,由于拉格朗日对偶问题是凸问题,那么二者之间的最优解存在一个 gap,称之为 拉格朗日间隔。只有近似解足够好,拉格朗日间隔足够小,我们就认为可以接受。
如何消去
万一无法求出
如果
- 第一个不等式:下界定义
- 第二个不等式:由于
满足约束条件,那么 ,同时 ,以及 。
因此,对于对偶变量有 $ \boldsymbol{\lambda} \geq \mathbf{0}, \Gamma(\boldsymbol{\lambda}, \boldsymbol{\mu}) \leq f\left(\boldsymbol{x}^{*}\right) $。即对于任意可行解,拉格朗日对偶函数小于等于原函数。
如果原问题是凸的,那么有:
此时对偶问题的解就是原凸问题的解。否则是严格小于。
SVM 的对偶问题
Soft-SVM 的原问题:
一共有
同时对偶变量的可行解区域 Dual Feasibility 为:
消去原问题的所有变量,拉格朗日函数对原问题变量求导:
求完导数之后
因此 Soft-SVM 的对偶问题就是:
注意:消去原变量的过程中可能引入新的约束。而
对偶问题的作用:原问题带有仿射变换,而对偶问题只是一个 box 和一个简单一点的仿射约束。原问题有
SMO 是使用迭代的控制变量法,假设任意两个变量
利用
对偶问题的几何含义
回顾 Soft-SVM 的 KKT 条件的几何解释:
- Dual Feasibility:
- Primal Feasibility:
- Slack Condition:
- Primal Feasibility:
- Slack Condition:
考察
由
支持向量可能会在夹板里面或夹板上。
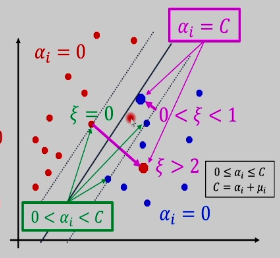
- 当点在上下夹板之外的时候,
- 当点在上下夹板之上的时候,
,此时要求 导函数反向, ,因此, - 当点在上下夹板内的时候(可能在内,可能在反例的地方):
,因此 ,所以
最后的解就是支持向量的线性组合,SV 显然是很少的,那么 SVM 是否能够得到稀疏解呢?稀疏解的好处就是算的快。这件事对现实世界不成立,SVM 的结果一般是不稀疏的(SVM 的一大缺点)。
随机梯度下降
偏好:不带约束的问题。能否对 SVM 用随机梯度下降呢?SGD 能解决 线性约束的二次优化问题 Quadratic Programming with linear constraints 吗?
写出问题的矩阵形式,直接调包!矩阵运算是经过优化的,比手写 for 循环好很多。
Soft-SVM 的原问题:
首先自变量有三个,将它写成向量形式:
因此:
照理来说,对偶问题约束简单,应该更快,但是由于它的优化函数是
结构风险最小化
正则化风险最小化:我们希望机器学习模型符合我们的损失函数范式:宁可要正则项也不要约束项:
引入 合页损失函数 Hinge Loss:
- 预测值:
- 真实值:
- 对于线性假设:
我们可以证明带约束的 SVM 等价于下面的不带约束的 SVM,这也是 SVM 走过的最大的弯路。首先回到 Soft-SVM 最初始形式:
将约束消去就是将
分类讨论:如果
机器学习的四大损失函数:
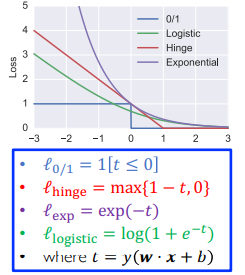
- 01 损失函数:如果 score 错了,那么损失为 1,否则损失为 0
- 合页损失函数:当
时就是在夹板外,没有损失,当 时,有损失,按照线性惩罚 - 指数损失函数:Boosting
- 逻辑斯蒂损失函数:Logistic Regression
那直接将
GD 方法直接求解不可行,因为 Hinge Loss 有一个点不可导。采用次梯度,令
参数更新方程
如果目标函数是强凸的(二次项是强凸的,合页损失不是强凸的,加起来就是强凸的),有一个更快的方法。
输出:#TODO 为啥要求平均值。
支持向量回归
Support Vector Regression:SVR,不要推导对偶问题,这个直接用 SGD 求就行(换了个损失函数)。