第二章 K 近邻
机器学习对数据有很多不同的视角进行处理:代数视角,统计视角,几何视角等。K 近邻,KNN 就是一个几何视角。我们通常会对数据进行特征提取,得到一个高维的特征向量,而这些特征向量就存在于高维欧氏空间中。以
在这个模型中,我们有一个基本假设:相似的数据应该具有相似的标签/类别/语义,也就是所谓的物以类聚 Birds of a feather flock together。但是近邻法是一种分类方法,而不是聚类方法。
近邻方法
最近邻
近邻 Nearest-Neighbor,NN:表示和某个数据点距离最近的数据点。以二维空间为例,我们定义样本点
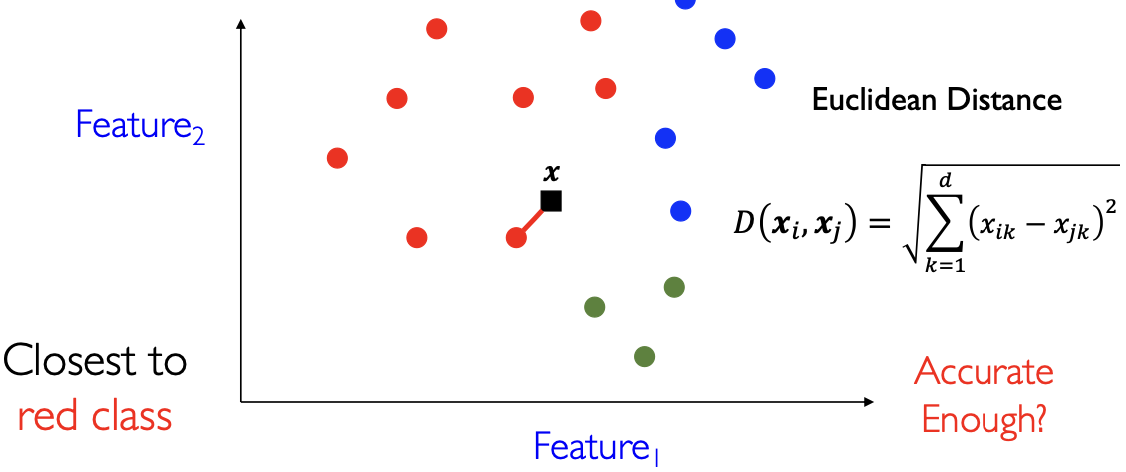
首先对于训练数据,我们将其画在二维平面中。对于验证集中任何一个的样本点
K 近邻
K 近邻,KNN 就是考虑样本点的
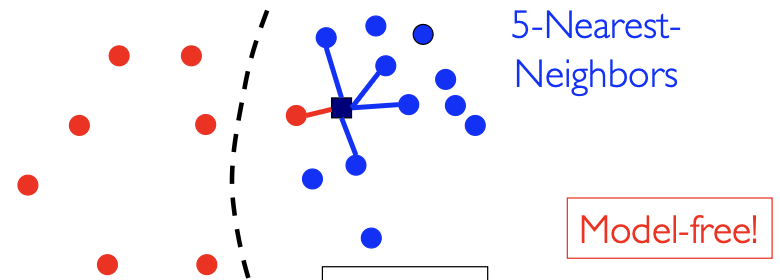
如图所示,尽管样本点
K 近邻方法非常简单,但是它是否能奏效 work 呢?1969 年由 Cover & Hart 证明了 K 近邻方法是对连续分布的一个很好的逼近器。他们证明了,如果数据可以较好地划分,那么 K 近邻方法可以收敛到一个几乎完美的解,错误率很低:
其中
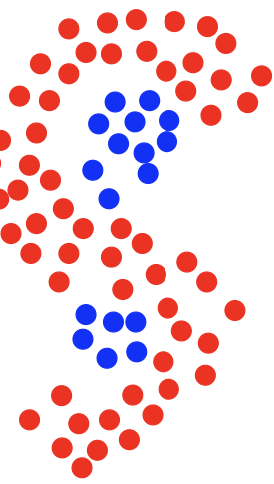
例如这种 S 形分布的异或问题,大多数参数分布方法都不能很好地解决。当然,近邻方法需要足够多的训练数据作为支撑。
同时 K 近邻是经验有效 Empirical Efficacy 的,即在很多领域都已经有了很好的应用。
超参数
K 近邻中只有唯一一个超参数
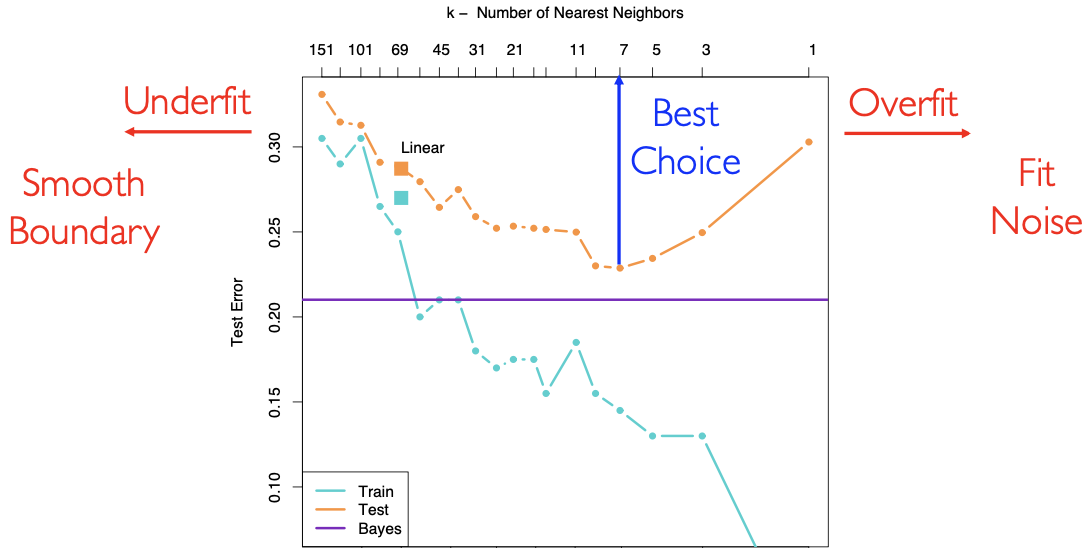
这是一张调参图。可以看到:
归纳偏好
K 近邻有两个归纳偏好 Inductive bias:即人为设置的前提条件:
- 欧氏空间中距离相近的点具有相似的标签
- 欧氏空间中不同维度之间是平等的:这是因为我们在计算欧氏距离时各维度权重为 1
这就导致如果不同维度特征的量纲差距较大时,直接使用 K 近邻法得到的决策面不好,如下图横轴为身高,米为单位;纵轴为体重,斤为单位:
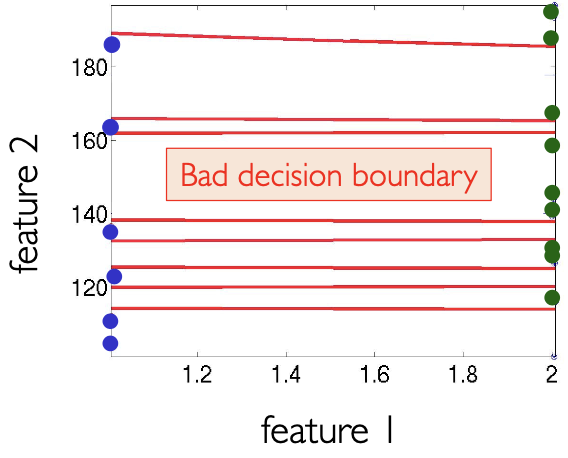
特征归一化
因此,我们需要做特征归一化 Feature Normalization,将每个特征都归一化为均值为
随后将该维度归一化为:
此时每一个维度从统计意义上来说都是均值为
距离选择
- 余弦距离 Cosine Distance:
- 两个向量夹角的余弦值大小
- 闵可夫斯基距离 Minkowski Distance:
时为曼哈顿距离/城市块距离 时为欧氏距离
- 马式距离 Mahalanobis Distance:
是正定矩阵,一般是单位阵或对角阵,由先验知识确定 时为欧氏距离 为对角阵时刻画了特征的重要性,从数据中学习 被称为度量学习 Metric Learning
- 还有其他距离:https://en.wikipedia.org/wiki/Distance
- 总结:没有一个距离总是表现的比其他距离好,就和算法一样
加权 K 近邻
普通 K 近邻 Vanilla KNN 使用少数服从多数的投票机制 majority vote 来预测离散值输出。而加权 K 近邻 Weighted KNN 则认为越近的邻居拥有更高的权重,加权方法也是机器学习中的一个重要方法。下面是以距离为权重的两个例子,其中
分类问题:越近的样本投票时权重更大:
回归问题:KNN 也可以做回归问题,输出值为
加权后可以使得分类面更加细致。除了上面给出的平方反比函数,还有很多加权函数。
近邻中心分类器
近邻中心分类器 Nearest Centroid Classifier 是对 KNN 算法的一点简单改进:假设给定训练数据集
在预测时,只需要比较验证集样本点
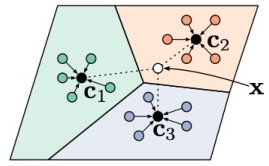
近邻中心分类器的好处是非常快,对比普通的 KNN 算法:
| 近邻中心分类器 | 普通 KNN | |
|---|---|---|
| 训练 | 计算每个类别的中心 | 不需要训练 |
| 验证 | 比较样本和类别中心距离 | 计算样本和所有数据点之间的距离并取 |
一般来说都有
近邻中心分类器有独特的归纳偏好/归纳假设/适用范围:它认为每个类中的数据点都服从以类中心为均值,某个协方差矩阵(单位阵)为方差的高斯分布。当我们做完归一化处理之后,数据点就都服从协方差矩阵为单位阵(但是均值不同)的高斯分布。反过来想,如果数据点都服从上述假设,那么显然距离类中心最近的点自然落入该类之中,因为高斯分布的等值线是形状相同的同心圆。
这个假设是一个非常强的假设:每个类中的数据点都服从以单位阵为方差,以类中心为均值的高斯分布,现实世界中基本不存在这种数据点。那么我们什么时候可以使用这个分类器呢?机器学习中有一个重要原理:越强的假设意味着越多的先验知识,也就意味着越少的数据量。因此近邻中心分类器可以用于小样本学习 Few-Shot Learning,FSL。目前仍然是小样本学习分类器中的最好 State-Of-The-Art,SOTA。
维度灾难
维度诅咒 Curse of Dimensionality 是导致很多机器学习算法失效的重要原因。
近邻搜索
近邻搜索:从所有的数据点中找到和某个点距离最近的
如果对于 KNN 算法采用一种新式数据结构 k-d 树来存储,那么需要
综上可知,使用 KNN 算法,只有在训练样本足够多,样本数据维度比较小的时候才有效。也就是说 KNN 算法在低维大规模数据方面很有效。
对于高维大规模数据,目前比较好用的方法是快速近似近邻搜索 Fast Approximate Nearest Neighbor Search,我们常用的以图搜图就是这个技术。
维度诅咒
上面是以近邻搜索的角度介绍了维度越高,搜索速度越慢这一维度诅咒现象。接下来我们介绍一种更加严重的维度诅咒现象:首先,我们的高维数据一般会分布在某个低维流形 manifold 之上,而不是弥散在整个高维空间中(好比宇宙和恒星),但低维流形的具体形状是一个先验知识,我们并不知道。而如果高维数据充分随机分布在高维空间中,此时我们会发现:
假设我们每一维的数据都位于
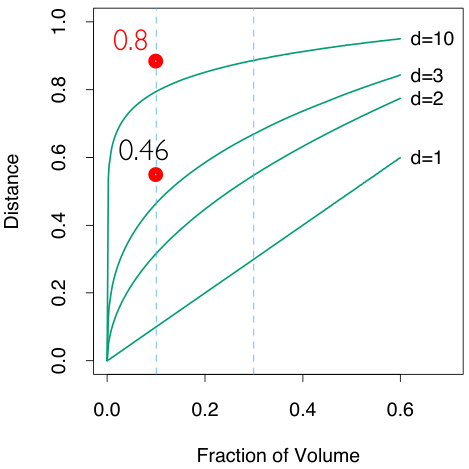
因此,为了获得足够多的信息,我们需要数据条数
《ESL》:考虑
当 n=500,d=10 时可知 med=0.52,此时也就是说,大多数数据点不再靠近球心,而是靠近球壳。也就是说靠近球壳的体积占据了整个单位超球的绝大部分(几何概型)因此几乎所有统计分布/直觉 intuition 都失效了,例如高斯分布的绝大多数不再位于均值附近,而是位于边缘部分。因此 KNN 也不再适用!
虽然总是在说维度诅咒,但是流形分布这个先验知识让我们有了继续学习高维数据的能力!我们机器学习的目的就是学习到这个流形,深度学习某种意义上就解决了这个问题——在深度特征意义下高维数据一般就位于了某个流行之上。
总结
- 什么时候使用 KNN:
- 特征维度比较低,单个数据点不要有太多特征 Few attributes per instance
- 训练样本条数足够多,足以对抗维度诅咒(维度越高数据距离越远,不是近邻)
- 优点:
- 无脑 agnostically 学习复杂的目标函数
- 不会损失信息:存储训练原始数据
- 训练数据条数可以很大:搜索引擎广泛运用 KNN 技术
- 类别数也可以很大:大多数机器学习算法在类别数特别大的时候会失效
- 缺点:
- 推理得非常慢 Slow at inference time,因此一定需要加速:快速近似近邻搜索:FAISS
- 高维不是很有效:维度诅咒
- 很容易被无关特征欺骗:特征工程 feature engineering 很重要