第三章 线性模型
回顾一下机器学习的基本框架:
- 任务是求出未知的目标函数:
- 给出一组训练数据
- 选定一个假设空间
:具备正则性 - 通过某个学习算法
从假设空间中找到最优的假设函数 - 目标函数有时也叫最优分类器 Optimal Classifier
- 目标函数在数据集上的错误率称为贝叶斯错误率 Bayes Error
显然,线性空间就是一个具备正则性的假设空间。接下来我们介绍线性模型的学习算法。
线性回归基本概念
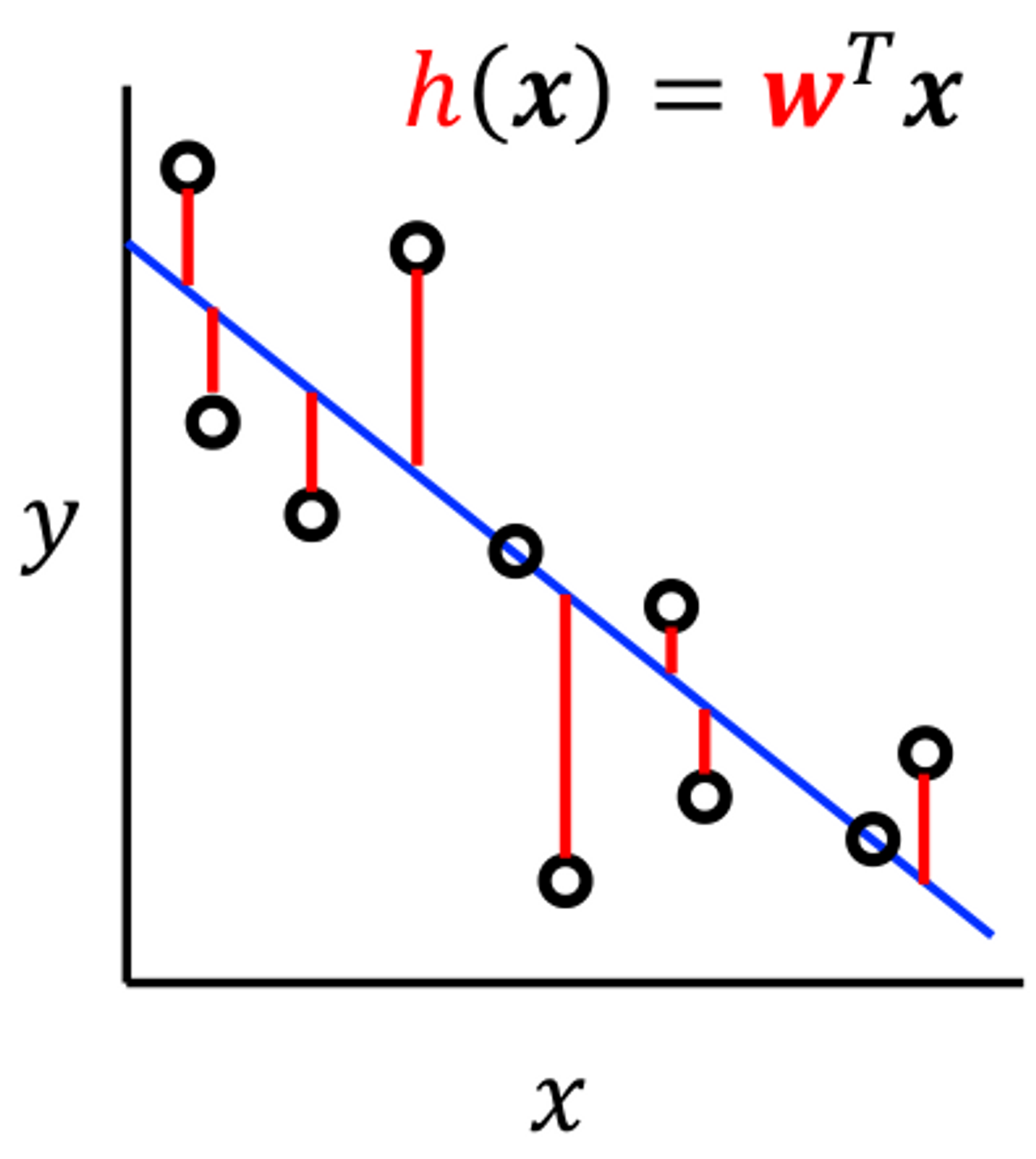
用电量预测
先看一个简单的例子:用电量预测。我们需要预测夏季的用电量,已知信息为如下表格:
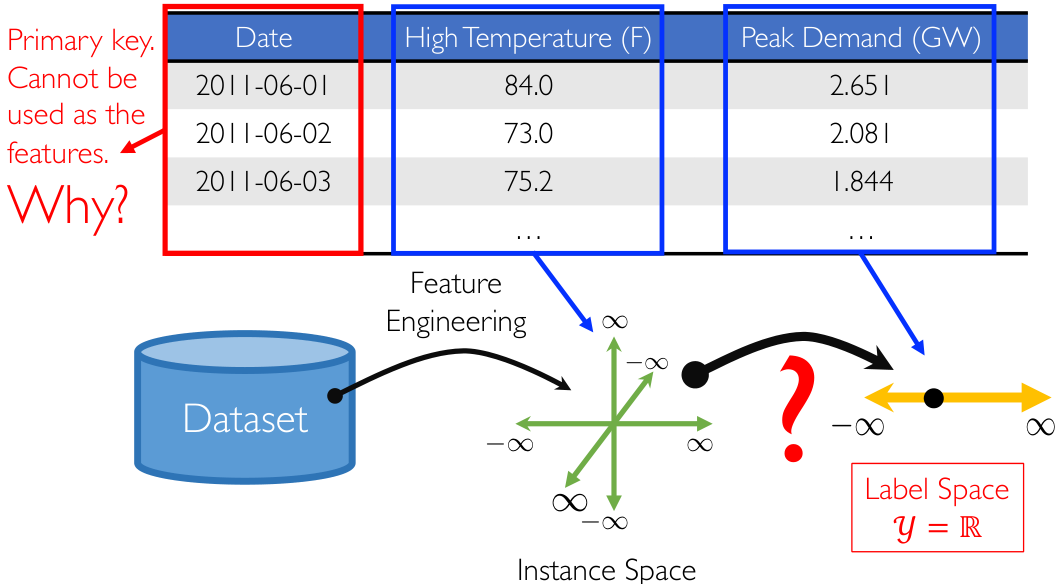
注意到:主键 Primary key 是不能作为特征的。因此我们可以对表格数据做特征提取,将每日最高温度作为特征,在特征空间/实例空间 Instance Space 中画出来,显然这是一个
这个映射应该是一个什么类型的函数呢?一般不会瞎猜,而是对数据做探索式数据分析 Exploratory Data Analysis,EDA 的前置步骤,通常就是对数据做可视化处理。
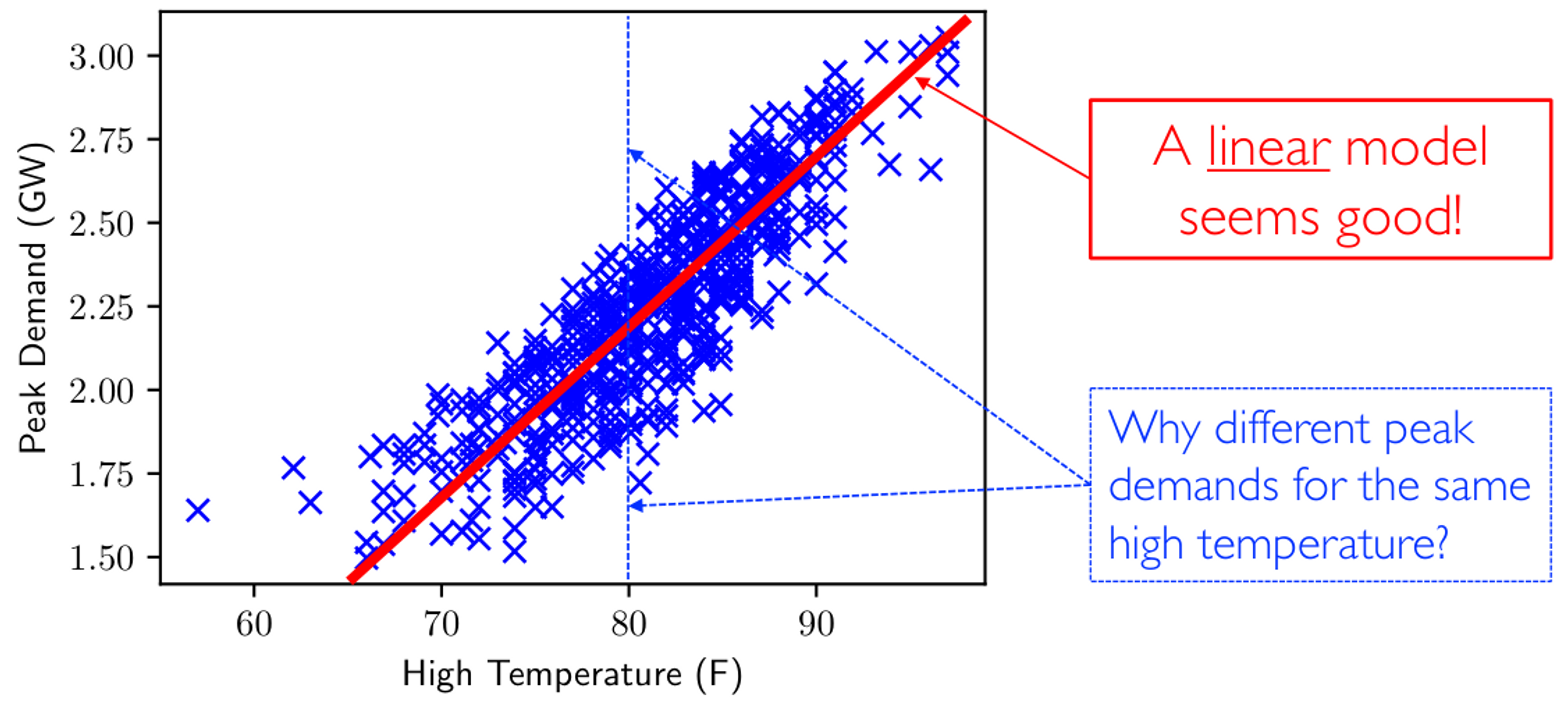
我们发现线性模型看上去拟合程度不错,但是仍然存在一些问题:为什么有些相同的温度对应了不同的用电峰值呢?这是一种不正常的现象。模型不完美的原因可能是:用电峰值不仅仅和温度有关,还和其他特征有关。EDA 阶段可以帮助我们找到假设空间,发现特征之间的强相关性……
线性假设空间
由于输入数据
其中,
同时
损失函数
这是一个回归问题,采用均方误差损失 squared loss/L2 loss 来计算训练集上的误差:
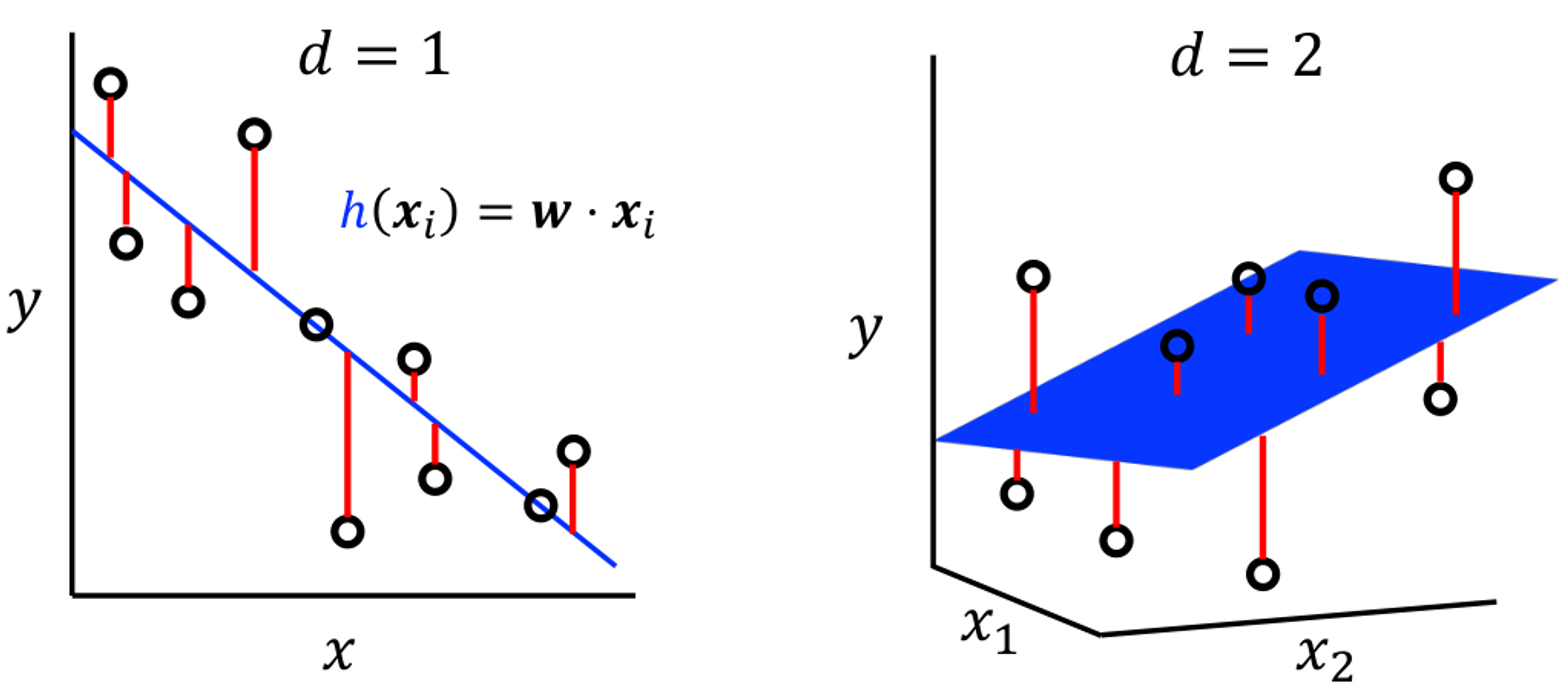
我们一般将
我们的目标就是最小化损失函数之和,也就是最小化训练误差,这就是我们的优化目标:找到一个最优超平面(对应的法向量
解析解
我们将线性回归的训练误差写成矩阵形式:
此时引入了两个矩阵,分别是数据/设计矩阵
因为
接下来就是考察
我们将最后的式子称为正规方程 Normal Equation,我们可以发现最后的式子复杂性太高:矩阵乘法的复杂性为
优化方法
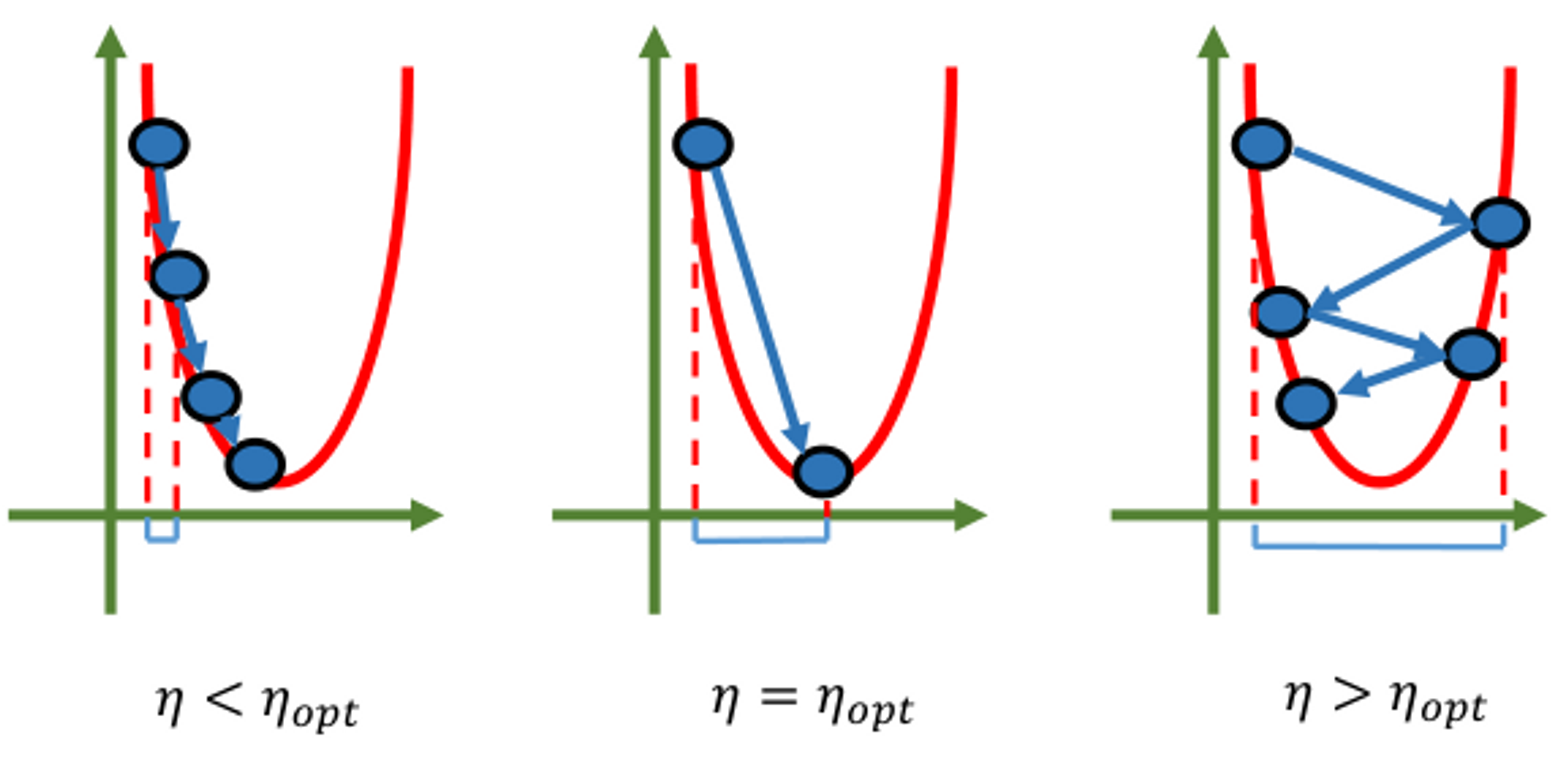
由于正规方程的解析解计算起来复杂度太高,同时实际应用中有很多方程是很难求得解析解的。因此我们考虑一种通用的优化方法——梯度下降法 Gradient Descent,GD,它适用于绝大多数可微的损失函数。沿着梯度方向,函数值下降最快(梯度的定义:最大的方向导数,即沿着该方向函数的变化率最大)。
梯度
首先对向量函数求每一维的偏导数,然后将其串成一个向量,就是梯度向量:
对向量函数
沿着梯度方向走一小步
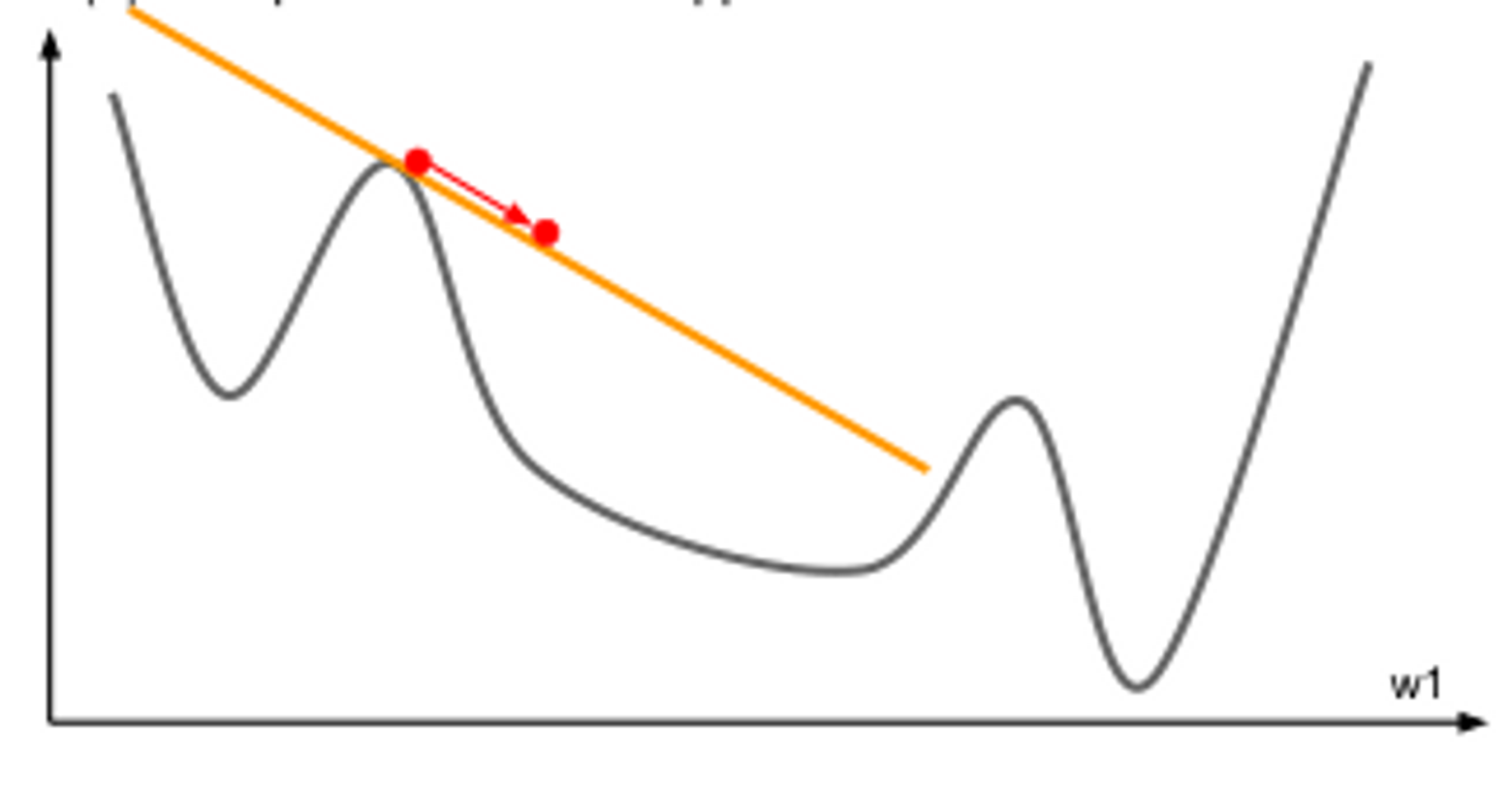
此时显然有
梯度下降算法能够找到凸函数的最小值。
梯度下降算法
通用优化算法:迭代式程序
- 对于每一轮迭代
- 当参数向量
还没有收敛,即对应的函数值还不是极值 - 更新
- 当参数向量
- 把
称为学习率 learning rate,是一个很重要的超参数(在深度学习中更加重要) - 理论表明,在凸函数下,收敛速率为
,当迭代 次,误差下降为初始值的 - 在线性回归(是凸函数)中,只需要算出梯度即可:
- 更新
- 算法的复杂度主要来自于梯度的计算:
- 更新
矩阵乘法中,小的矩阵要优先乘,即先算后面的向量。
随机梯度下降
我们发现,每一步都要计算当前点的梯度
- 对于每一轮迭代
随机从数据点中选择一小批数据 minibatch:
计算这一小批数据的经验误差:
计算这一小批数据的梯度:
更新参数:
- 对于线性回归就是:
- 更新参数:
- 计算复杂度:
- 更新参数:
- 深度学习基本都使用 SGD 方法,因为它是最快的,只与维度和迭代次数成正比
- 理论表明,在凸函数下,收敛速率依然是
统计视角
参数化模型中的似然函数
在线性回归中,为什么要用均方误差作为损失函数呢?我们从统计视角来回答这个问题。
假设我们有一个以
也就是运用了独立同分布概率的乘法原理。为了避免数字过小导致下溢出,机器学习中往往使用对数似然函数 log-likelihood:
最大似然估计
最大似然估计 Maximum Likelihood Estimator,MLE 方法就是找到一组参数
同时,在特定的分布假设下,一个最大似然估计过程会对应着机器学习中的一个损失函数。
判别模型
在监督学习模型中,我们将训练数据集
其中
即对于
但是之后的学习理论课会告诉我们,即使在这么强的假设条件下,判别模型依然可以给出期望误差的一个估计,也就是说勉强能用!
将上述经验分布式代入条件概率公式得到:
因此对于判别模型,我们可以找到一组参数
那么判别模型的极大似然估计就是(拿掉了边缘分布):
高斯噪声假设
高斯噪声假设是线性回归模型的基本假设。我们认为标签值
也就是
因此输出标签的期望值为:
我们将这种期望
同时我们还有
假设条件概率分布符合高斯分布:
那么在全体训练集
做最大似然估计:
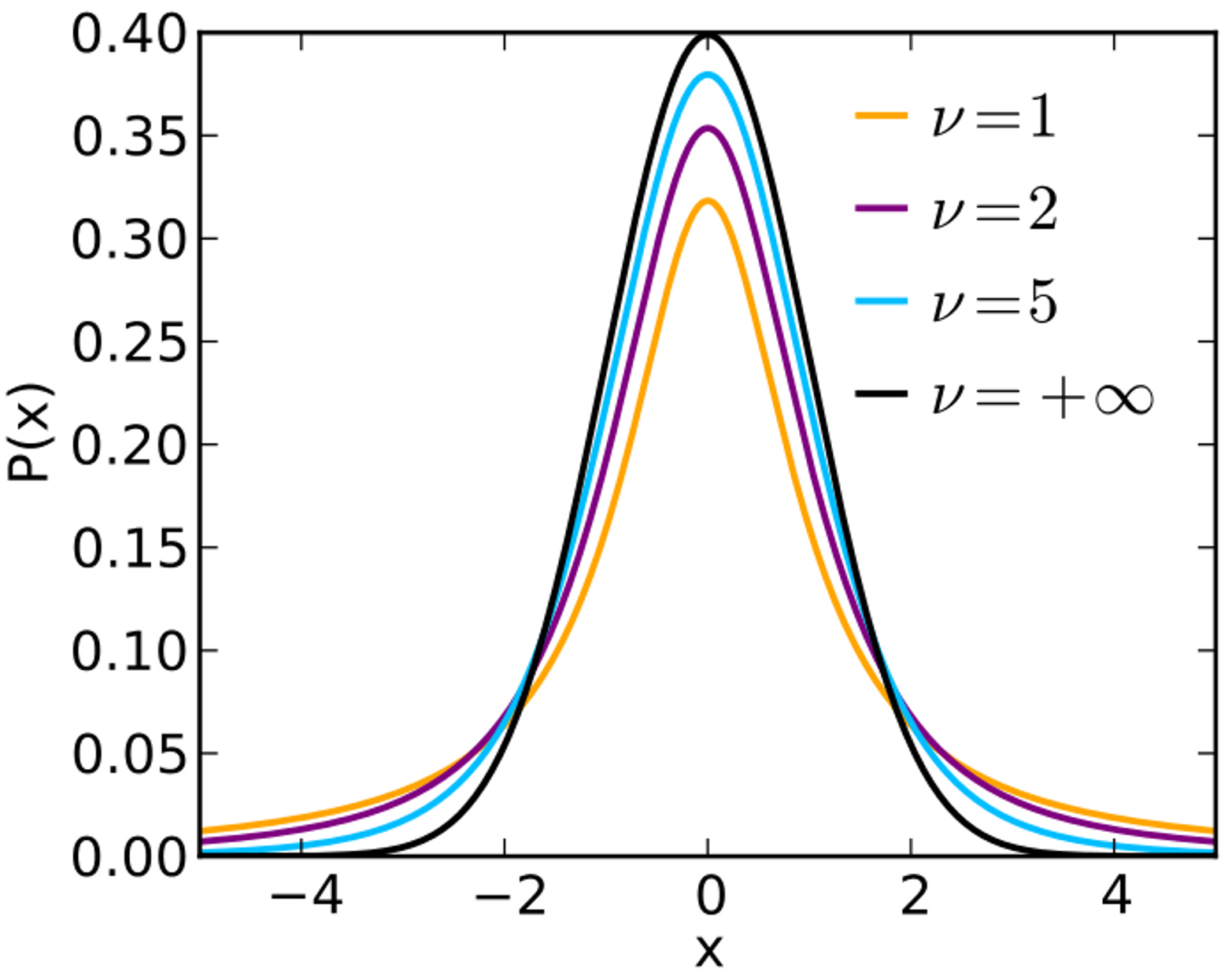
这就说明:采用均方误差损失的线性回归等价于高斯噪声假设下的线性模型的最大似然估计。那么如果噪声模型不符合高斯分布,那么就不能用均方误差损失作为损失函数!例如长尾分布 t 分布就有自己的损失函数/待优化的目标函数。t 分布主要用于对噪声本身进行建模。
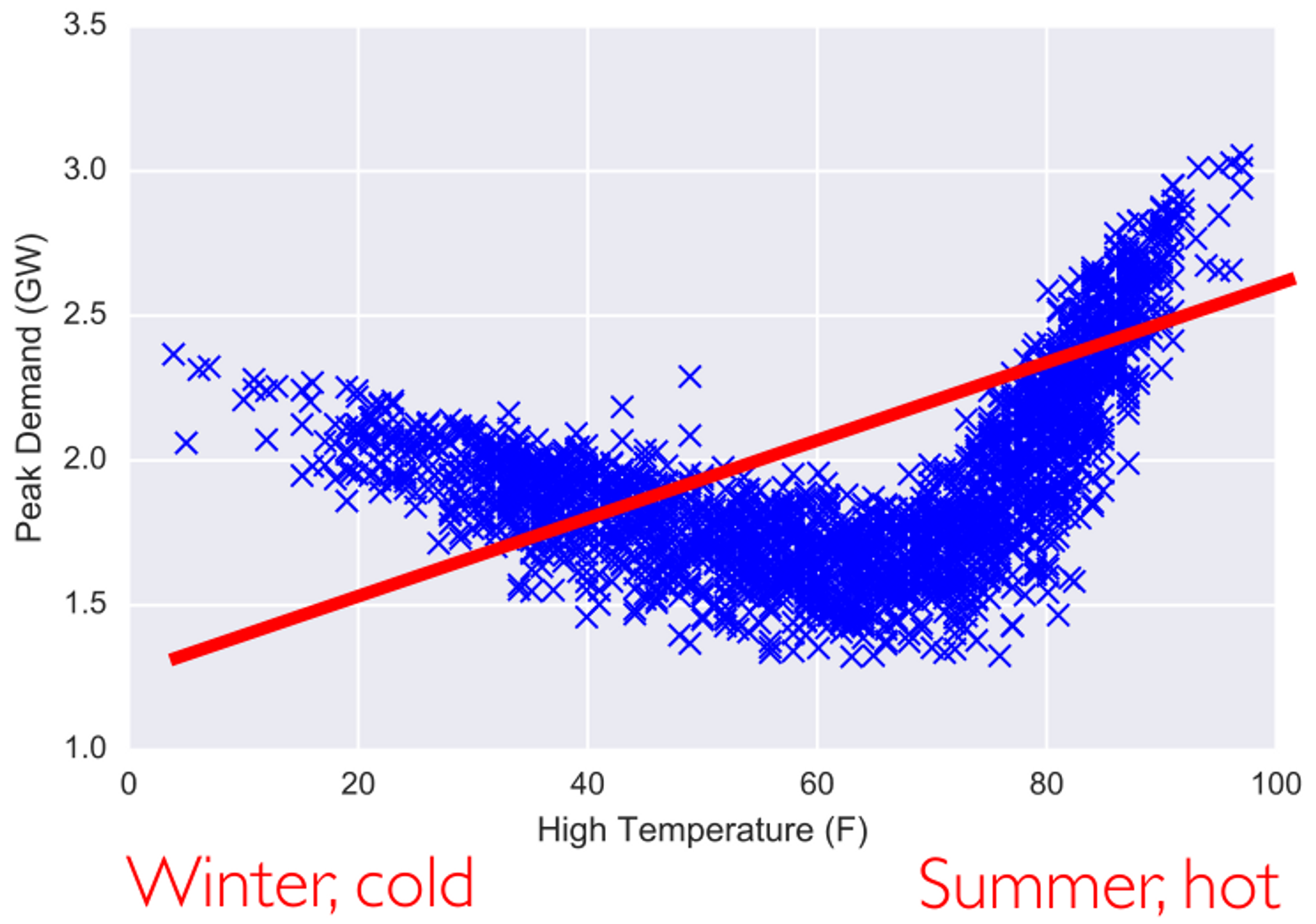
非线性化
首先,我们通过 EDA 模型发现这是一个非线性模型,如果此时还用线性模型,就会出现欠拟合:
基函数
基 Basis 的概念是从线性空间中引申而来的。特征映射:将特征向量
线性代数中就是矩阵变换,但矩阵是一个线性变换,我们要做的是非线性映射:即每个
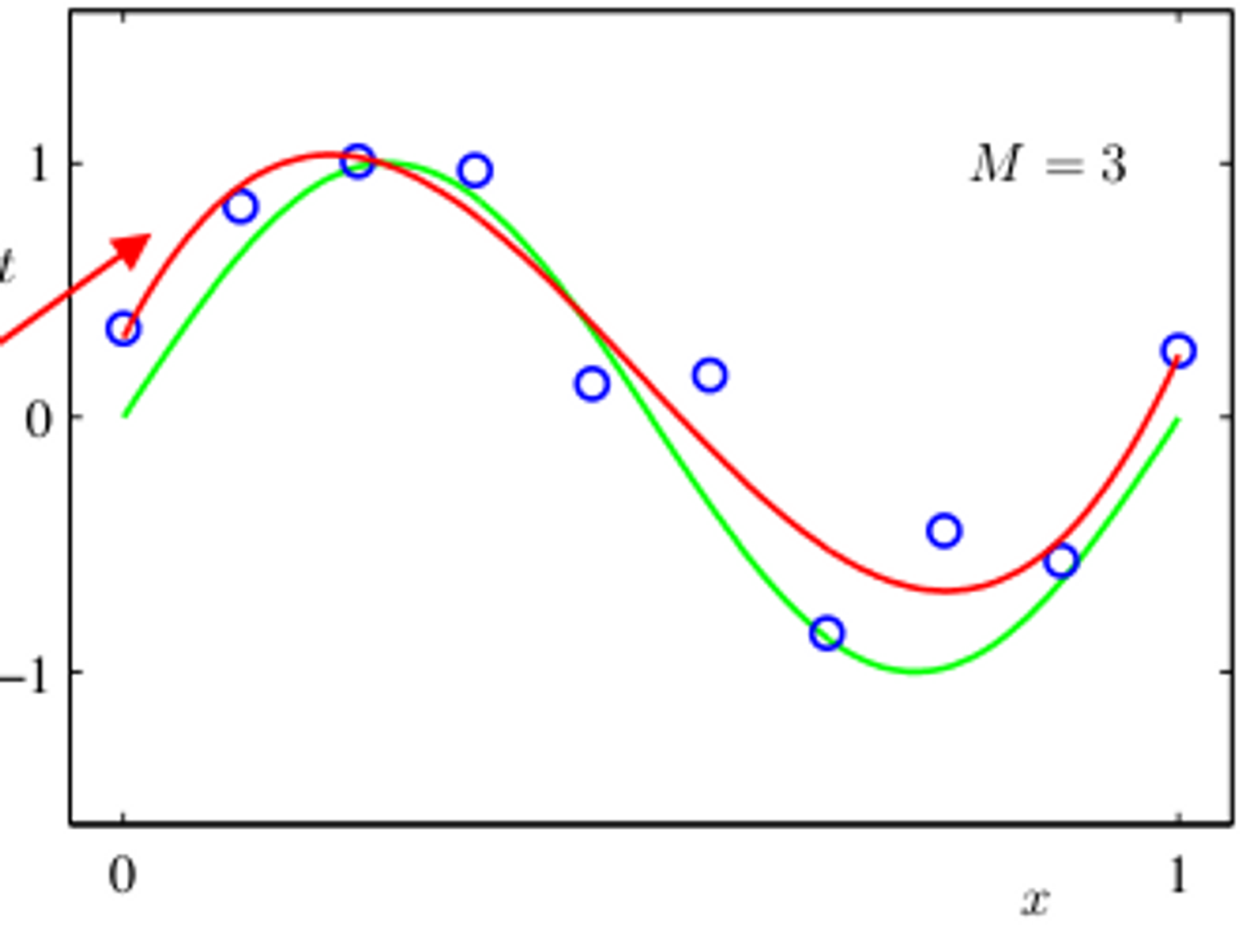
如图所示是一个三次函数,显然不能用线性模型拟合,但如果我们构造如下多项式基函数:
一共有 4 个基函数,它们将 1 维特征向量映射成了 4 维特征向量,以
问题在于:基函数该如何构造?不仅是高次多项式,甚至
机器学习中我们常使用径向基函数 Radial Basis Functions,RBF:
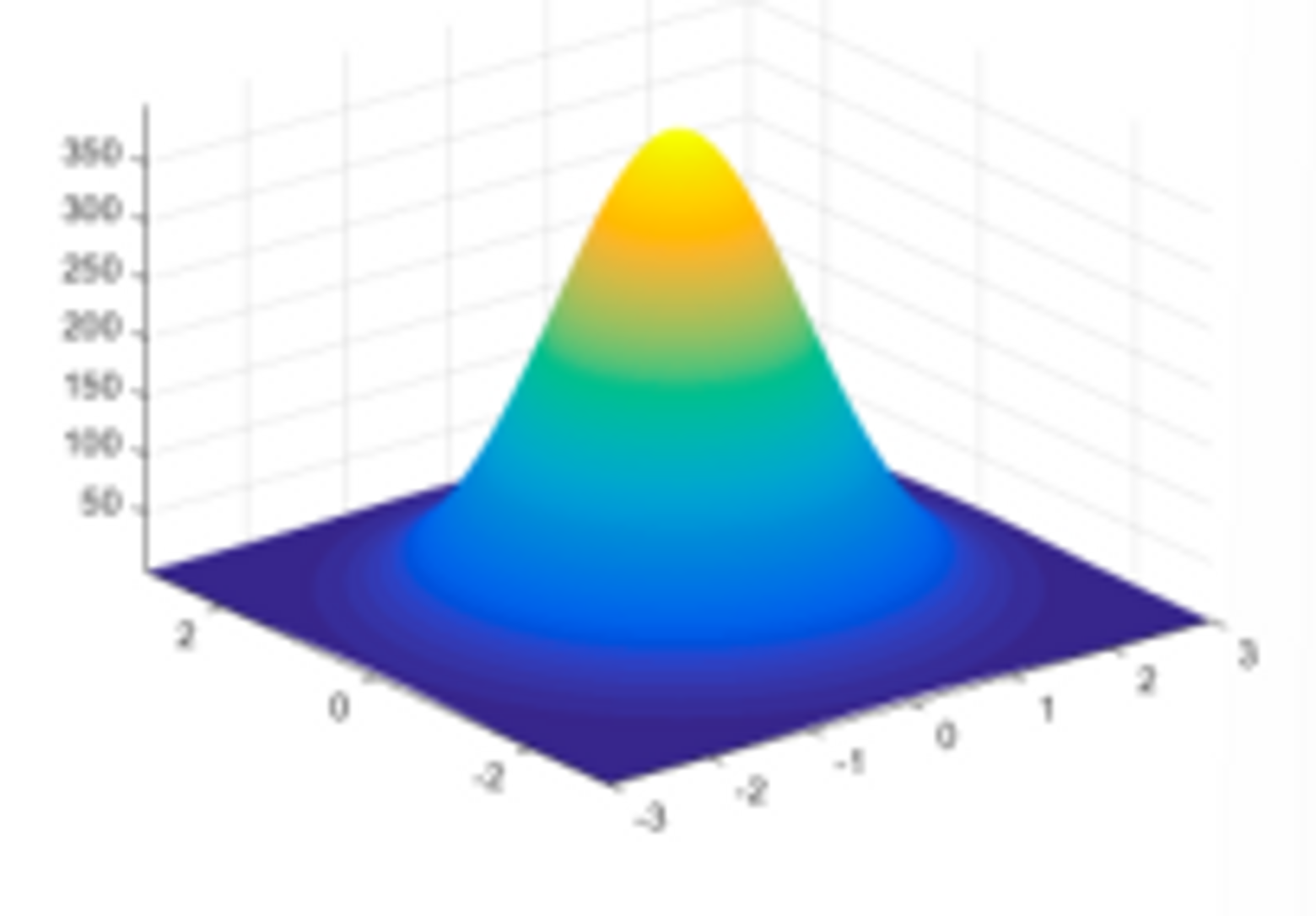
也称为高斯核函数。它将每一个数据
非线性化映射
非线性映射之后,我们会在新的特征空间
在整个式子中
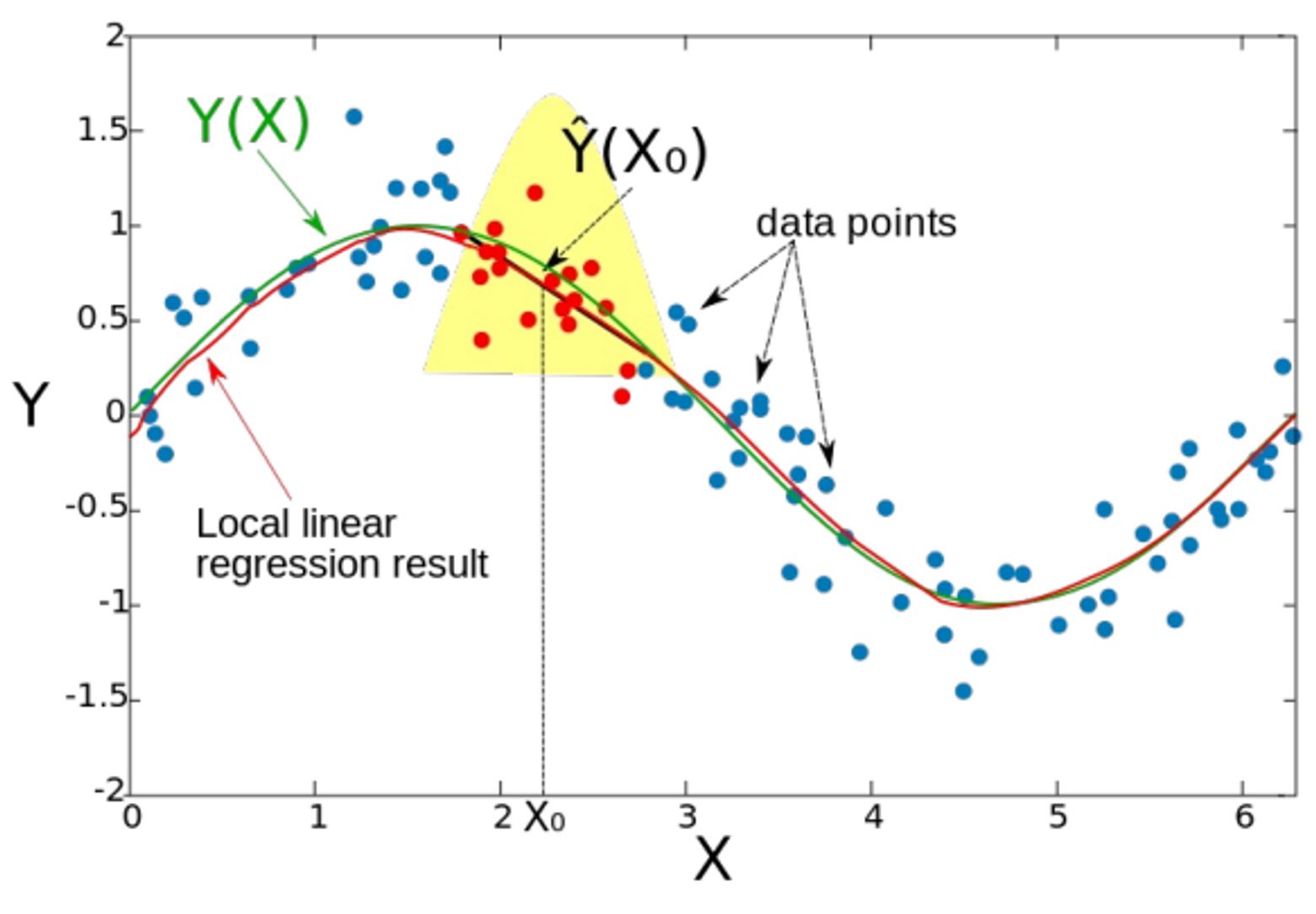
局部加权
在线性回归中引入近邻思想(没懂):
多选题:以下说法正确的是:
- 当类别数较大时,KNN 算法比线性模型更适合
- 使用 GD 或 SGD 求解线性模型,可在线性时间内求出全局最优解
- SGD 比 GD 单步更快,但需要更多迭代次数,因此收敛时间更长
- 使用基函数的线性模型也可以处理非线性问题,但需要特征工程
解答:线性模型是凸函数,可以求到全局最优解。SGD 和 GD 的收敛速率一样,但是单步更快,迭代次数更多,SGD 在实践中远远快于 GD,尤其是大规模样本,小到 LM 和 SVM,大到神经网络,全部用 SGD 进行迭代。线性时间就是和样本数/特征维数成正比(遍历数据所需要的时间)。
正则化
过拟合
高阶多项式的好处是:拟合数据的能力更强,但是过于高次的多项式容易拟合噪声 fit noise,产生过拟合 overfitting。同时另一种过拟合现象是如何实现分布外泛化,即训练数据只收集了一部分,在未收集到数据的区域,机器学习模型往往会失效——迁移学习。