第一章 基础知识
总的来说,深度学习是机器学习中的一种方法,通过神经网络从数据中学习特征,实现人工智能的一种途径。在计算机视觉中,深度学习在图像分类、检测/分割、图像生成等方面取得了重要进展;在自然语言处理中,深度学习在机器翻译、问答系统等方面也有很多应用;在音频处理等领域也有一些研究成果。不过,深度学习仍然有其局限性和挑战,例如数据量和质量的问题、模型可解释性等,这也是未来深度学习需要解决的问题。
深度学习介绍
- 人工智能:泛指使得计算机能够模拟人类的一些技术:感知、语言、情感、联想……
- 机器学习:实现人工智能的一种途径:不需要显式编程教会计算机某种能力
- 深度学习:机器学习中的一族方法:也是从数据中学习,但限制在使用神经网络学习特征
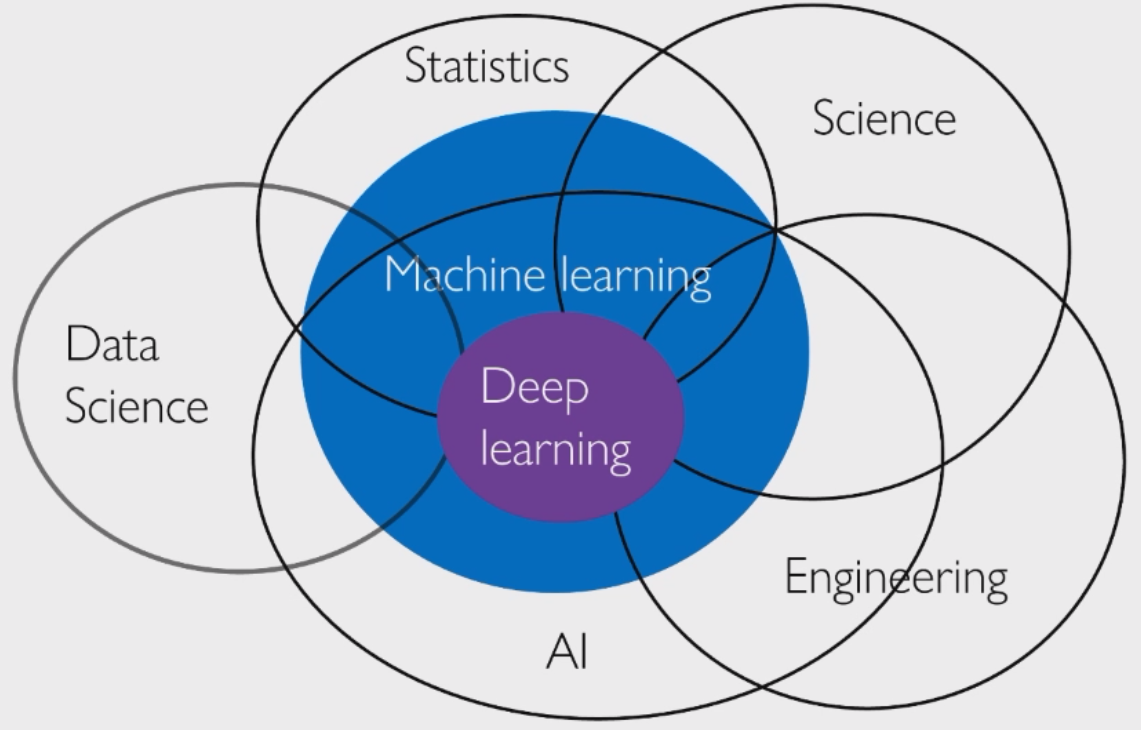
深度学习是最交叉的学科,2022 年是 AI+Science 元年,诞生了 AlphaFold 和反应堆;2023 年是 ChatGPT 元年,成功在 GPT 模型基础上诞生了具有划时代意义的聊天机器人。
计算机视觉
深度学习最开始成功的领域是计算机视觉 Computer Vision,尤其是在图像分类领域。神经网络在 ImageNet 数据集上(1M 数目,1k 类别)超过了人类,一般认为这个领域任务已经解决了。
另一类计算机视觉的任务是检测与分割 detect and segment,从图像和视频中检测/分割物体,可以说是计算机视觉中最重要的两类技术,也是很容易落地的技术,例如人脸识别,自动驾驶等等都需要这个技术。其中 https://github.com/matterport/Mask_RCNN 是该领域的最优论文。

第三类计算机视觉的任务是图像的生成,通过一句话描述,让神经网络生成各种风格的图像。目前最好的模型是由 OpenAI 开发的 DALL-E 2。这个技术是目前深度学习的热点:扩散模型 Diffusion model。

自然语言处理
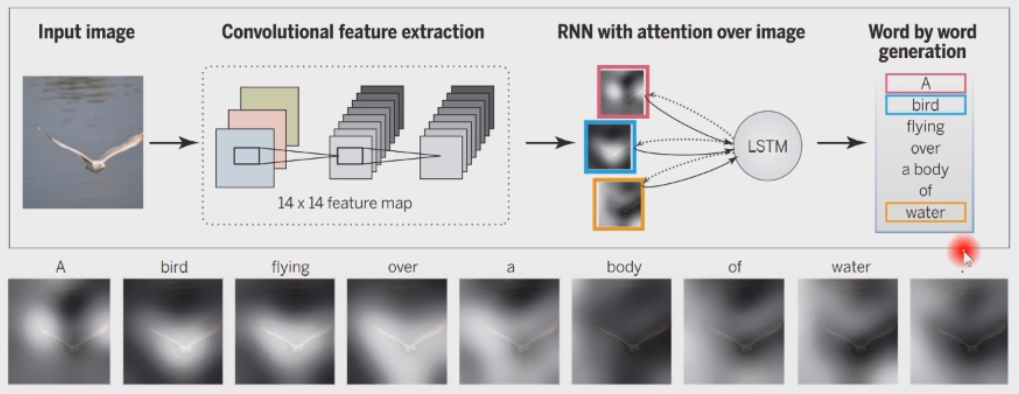
自然语言处理 Natural Language Processing,NLP 也是深度学习取得重要进展的一个领域。这其中最基本的任务就是机器翻译 Neural Machine Translation,NMT。下图说明了谷歌翻译并不是采用的词表翻译,而是深度学习技术,至于为什么会出现这种错误,先卖个关子。
另一个重要的 NLP 任务是问答系统。分为两种:一问一答或者看图说话:输入一张图片和问题,模型给出回答。Siri 等语音助手也是问答系统,但是目前还不够好,还有改进空间。Siri 首先进行语音识别,将语音转化为句子;再输入问答系统,得到答案;通过文本转语音进行输出。这是一个具有较长生命周期的系统,是多个算法的融合。
音频处理
音频处理 Audio Processing 也可以看作是生成模型的一种,可以用来生成各种音乐。目前的主流结构是 WaveNet:https://deepmind.com/blog/wavenet-generative-model-raw-audio/,AI 作曲目前已经超过了普通人类。
博弈
人们后来认为:深度神经网络作为一种通用的数学工具,不一定只有计算机视觉和自然语言处理这么简单的应用,应该有更大的作用范围。在博弈方面,目前来说做得最好的是 DeepMind,发了四篇 Nature 封面,从 2015 年最基础的 AlphaGo 到最后的通用模型 MuZero,这也是目前的一个趋势:从专用模型到通用模型。具体文章可以看:
- https://deepmind.com/research/alphago/
- https://deepmind.com/blog/article/muzero-mastering-go-chess-shogi-and-atari-without-rules
机器人
2017 年,人们开始思考如何教机器臂抓取东西?能否灵活使用双手是人和动物的区别。目前来说这一块是 Google 做的比较好:它是先从虚拟数据中进行强化学习,得到的模型再让机器臂在现实数据中进行抓取。元宇宙概念和这个理念较为相关:连接虚拟世界和现实世界的代沟。目前这个方向做的还不够好,也促成人思考:当前的技术路线是否正确?
医学
新冠肺炎疫情时期,2020 年一篇发表在 Nature 上的文章指出:可以用深度学习方法对肺部 CT 图自动进行扫描,识别病灶区域(注意力)以及是否是新冠肺炎患者。这是一个很成熟的技术在医学领域的小小应用,并没有实现难度,但是不一定有很好的效果。AI 技术往往错在误报漏报的情况,因此目前还不能替代人类医生,只能辅助人类医生。
生物学
2020 年,深度学习技术在生物学领域产生重大突破,DeepMind 旗下的 AlphaFold2 在 CASP14 比赛中准确率超过 80%:https://deepmind.com/research/case-studies/alphafold
地球科学
2021 年,DeepMind 的科学家用生成模型做大气云层的雷达回波,预测后 90min 的云层运动,取得了很好的效果。那么,既然天气都可以预测,是不是其他自然现象:地震、海啸等等也是可以预测的呢?
物理学
2022 年,DeepMind 的科学家使用深度强化学习模型做反应堆的控制。
计算机科学
2022 年 12 月,DeepMind 提出的 AlphaCode 做自动编程和自动代码生成。目前来说还没有让程序员失业,只是适度减轻了程序员的工作,例如 Capilot 工具做代码补全和提示。这篇文章《Competitive Programming With AlphaCode》发表在 Nature 封面上,第一作者是软件学院 2011 级毕业生李宇佳,他也是 DeepMind 的研究科学家。
从 Github 获得代码,从各种竞赛网站,如 Codeforces 获得问题,进行训练。
产业
AI 要赋能产业,推动生产力发展,四个面向:
- 面向世界科技前沿:哪个主要模型是我们发明的?
- 面向经济主战场:我们怎么赋能产业的?
- 面向国家重大需求:例如芯片制造如何用 AI 改进工艺?
- 面向人民生命健康
我们清华的同学不能只拘泥于简单的 AI 工作:短视频换脸等等,我们要心系国家,要认识到人工智能落地的复杂性和困难。
为什么是深度学习
给出一句话定义:深度学习算法是使用多个非线性变换结构从数据中进行高层的抽象:Deep learning is algorithms that model high-level abstractions in data using architectures consisting of multiple nonlinear transformations. 我们知道多个线性变换的组合其实本质还是线性变换,非线性变换才能产生非同构的空间。从仿生学角度中大脑的结构出发,人们发现人类的大脑其实是分层的,从感知层到认知层,从光信号变成认知信号。
特征是高层抽象的具体体现:
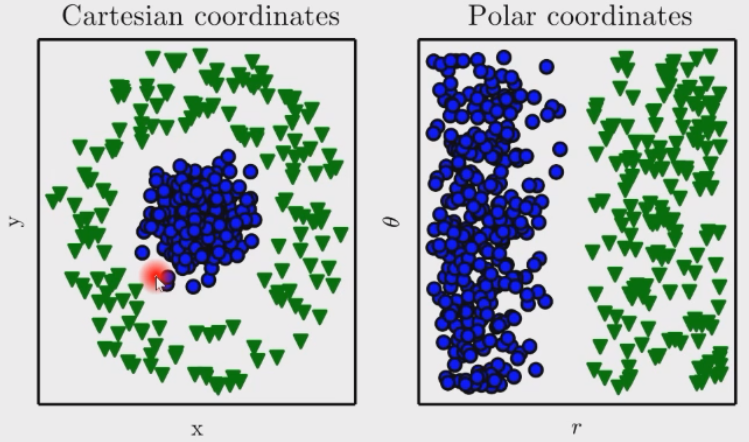
该分类问题在直角坐标系下这是一个非线性可分问题,线性可分问题是机器学习研究的重点。但是在极坐标系下是一个线性可分问题。在不同的坐标系下数据的分布不一样,深度学习就可以理解为坐标系的变换,经过每一层,高维特征就会发生变换。
刚才说的极坐标变换是一种非线性变换,这里介绍的平方变换也是一种非线性变换,经过这种非线性变换可以更简单地将非线性可分问题变为线性可分问题。
难道我们以后都需要根据领域知识去找特征,设计坐标系变换吗?但是在人工智能的发展过程中,一开始都是根据这种领域知识来提取特征,输入学习算法/坐标系变换,最后得到模型。例如计算机视觉做了 40 年的传统特征提取:颜色,纹理,深度图等等,直到在深度学习于 2014 年在图像识别领域取得重大进展的时候,仍有一批计算机视觉元老认为传统特征方法还有独特的用处。
特征学习
所以说,人们在以前都是靠手工去设计特征,而深度学习则是希望特征是一个可以学习的,手工设计的特征是十分耗时的:

上图是深度学习得到的人脸特征,首先从底层的线条/轮廓(边缘检测),再到中层的五官(局部),最后到高层的面部完整结构/语义特征。这种可视化技术也初步提供了深度学习的可解释性。
常见的系统分为以下几种:
- 规则系统:占比 70%,谷歌搜索基本使用规则系统,效果比使用机器学习的必应搜索好
- 传统机器学习:提取手工特征,再通过学习器
- 深度学习:不需要提取手工特征,让机器学习特征,再通过学习器
目前深度学习的前沿就是探讨:随着网络深度/尺度的增加,是否会引发某种质变?
计算图与神经网络
首先抽象出一个叫做计算图 computational graph 的数据结构,可以在其上做基本的代数/求导运算,同时还可以把这个数据结构抽象成一个网络层。下图就是逻辑斯蒂回归模型的计算图结构,先线性组合,然后通过一个非线性激活函数
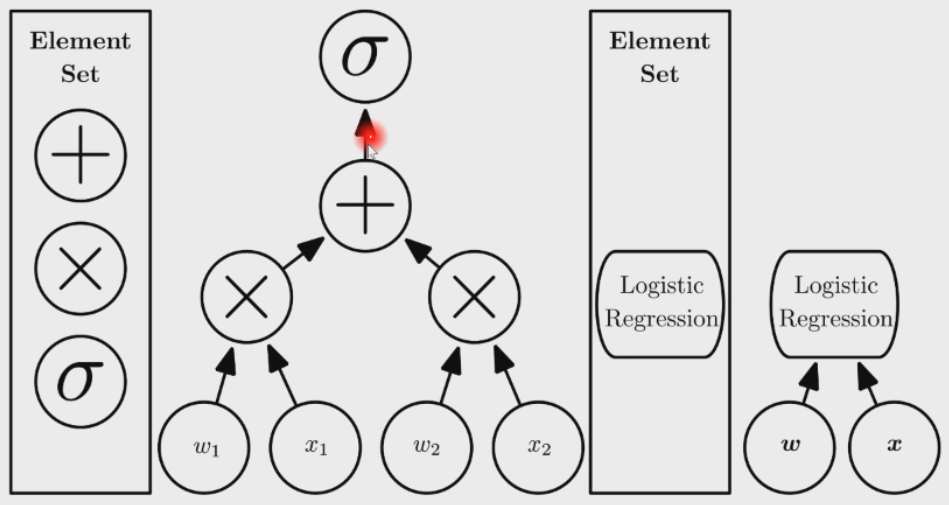
实现了这个计算图的软件就是 PyTorch,TensorFlow,MXNet 等等。因此我们就很容易实现各种复杂的神经网络。在 2014 年时如果想要写一个类似逻辑斯蒂回归的算子,就需要自己手写前向传播和反向传播,因此门槛就比较高。
深度学习的历史
- 1958 年,RosenBlatt 提出了感知机 Perceptron 模型
- 1969 年,感知机模型遭到了批判,认为它不能表达异或算子(非线性算子)
- 1969~1995 年,AI 寒冬,没有人开始做深度学习相关研究
- 1974 年,提出反向传播 Backpropagation 算法,没有人关注
- 1986 年,反向传播算法被再次发现,由于它可以求解多层模型,开始得到关注
- 1995 年,支持向量机 SVM 被发明(核函数方法可以处理非线性问题)SVM 很快,符合时代
- 1998 年,杨立昆 Yann LeCun 设计了卷积神经网络 CNN,应用于手写数字识别,可以商用
- 2006 年,Hinton 发明了受限玻尔兹曼机 RBM,并用其做数据的特征学习,取得了一些效果
- 2012 年,AlexNet 遥遥领先第二名获得了 ImageNet 竞赛冠军,标志深度学习的第一次浪潮
- 2012 年,谷歌大脑计划用 16k 的核学习了一张猫脸:GPU 计算,由吴恩达 Andrew Ng 领衔
- 2018 年,图灵奖颁给了深度学习三巨头(但并没有就此结束浪潮)
- ……
为什么是现在
深度学习三驾马车:
- 大数据:庞大的训练数据集,如 ImageNet(李飞飞创建)
- 计算机硬件:大规模并行 GPU 计算(NVIDIA)
- 计算机软件:PyTorch,TensorFlow 等在底层对深度学习算子做了高效 C++ 并行实现
机器学习概览
基本框架
泛化误差:
说明:要用一个尽可能简单的模型,在尽可能大的样本集上,获得一个尽可能小的训练误差。当且仅当在需要时才使用复杂模型。
早期用嵌入技术做可视化:t-SNE。
深度学习就是:结构化输入,结构化输出:因此深度一定带来了某些质变。
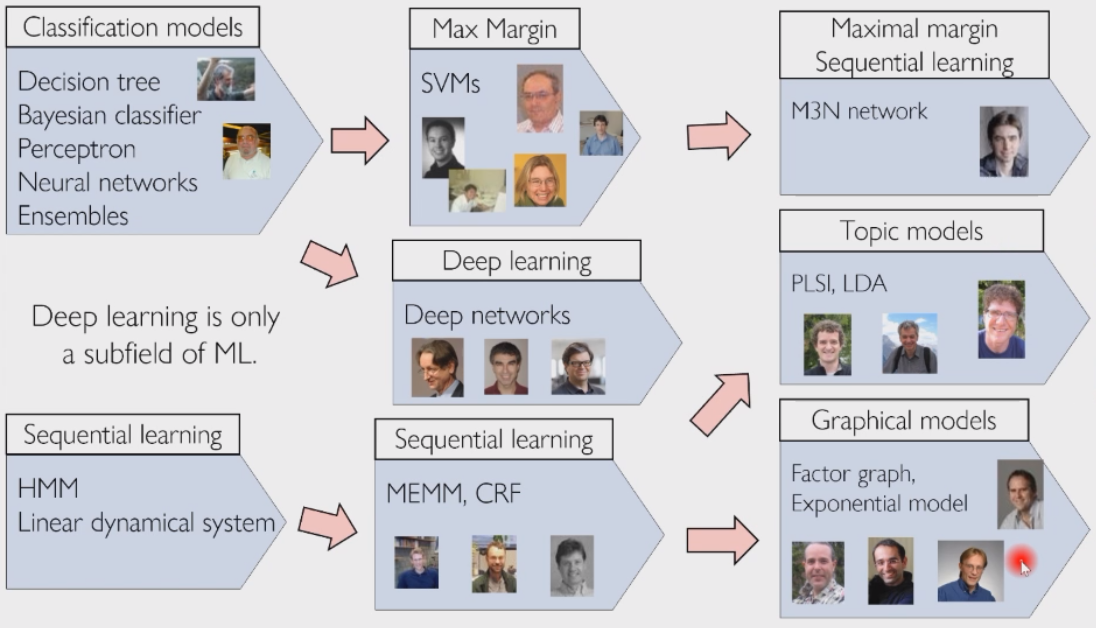
机器学习与深度学习流派:
贝叶斯网络不讲,但是扩散模型就采用了贝叶斯网络。
基础知识
机器学习中统一使用风险最小化框架作为学习目标:
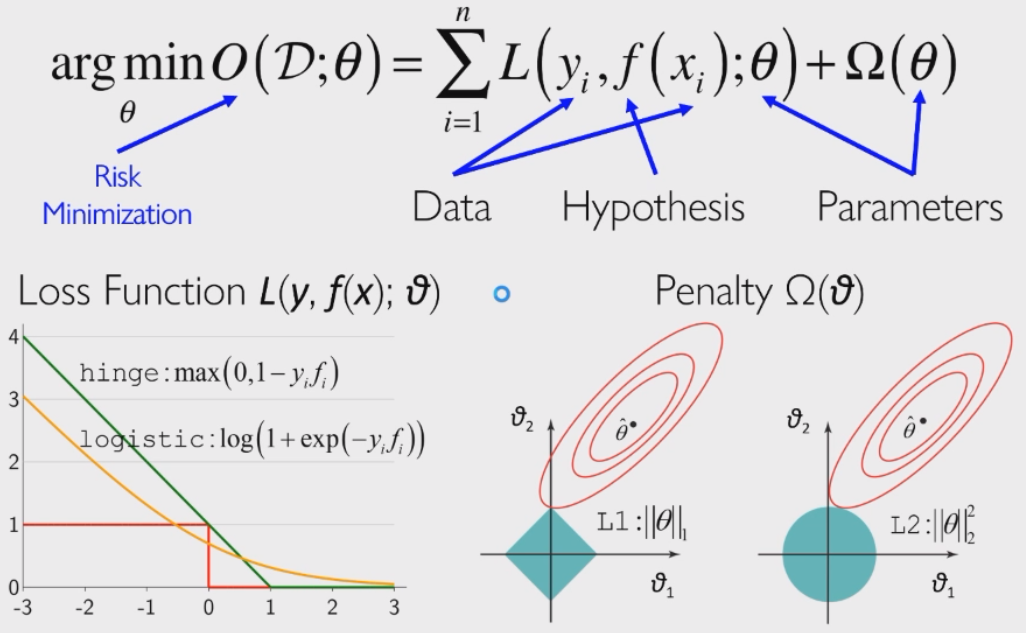
学习算法就是 SGD 算法。
线性回归
目标函数:
解析解:
复杂度太高,还是采用 SGD 求解。
逻辑斯蒂回归
目标函数:
近端梯度下降,因为一范数不可微:
一范数正则化具有特征选择的能力。
软最大回归
多分类:对于每一类,模型输出隶属于这一类的可能性。对于每一类,通过超平面打出分数,选择分数最大的作为输出:
为了让超平面的分数转化为概率分布,首先通过指数函数将
这就是机器学习的概率视角。那么软最大回归的目标函数为(这个损失函数是对数似然函数):
也称其为交叉熵损失函数 Cross-Entropy Loss,那么优化方法为:
优化
最优超平面就等价于损失函数最小:
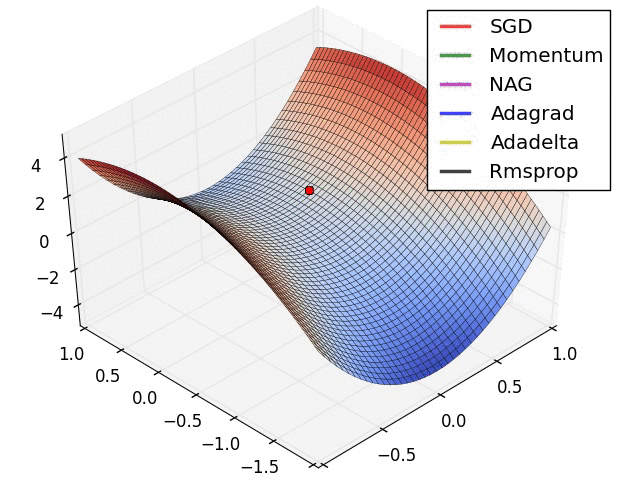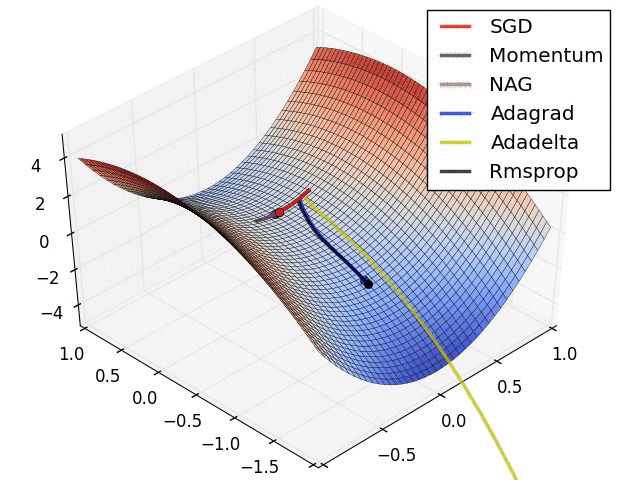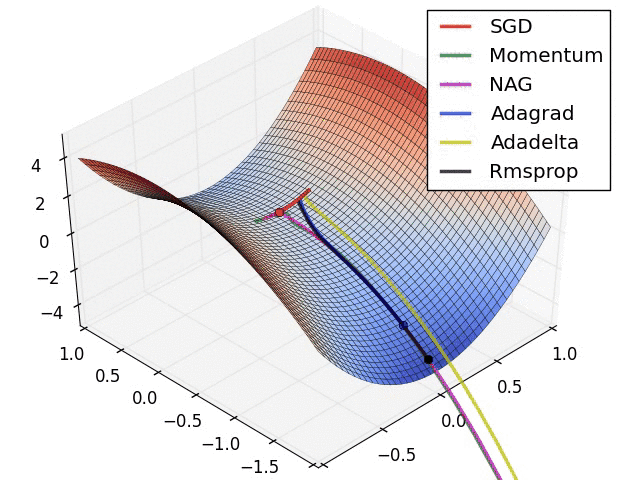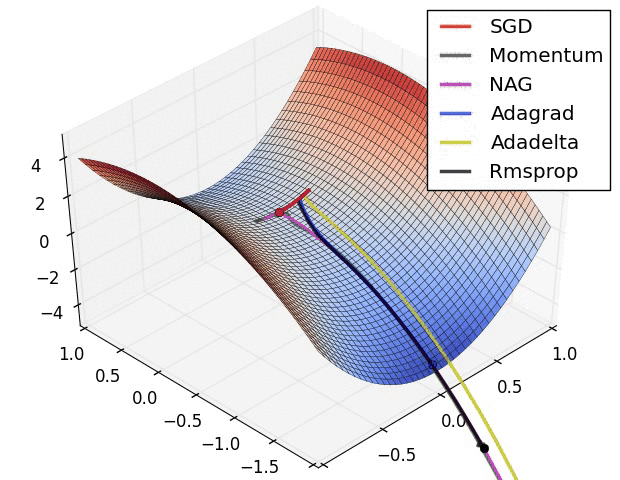
参数化与非参数化
- 参数化模型:含有显式的参数
- 非参数化模型:本节课不讲
- KDE:Kernel Density Estimation
- KNN:k-Nearest-Neighbor
近似与估计
深度学习几乎没有近似误差,但是有估计误差,因此我们会用一些技巧。
泛化和模型容量
模型越大,泛化性越差:
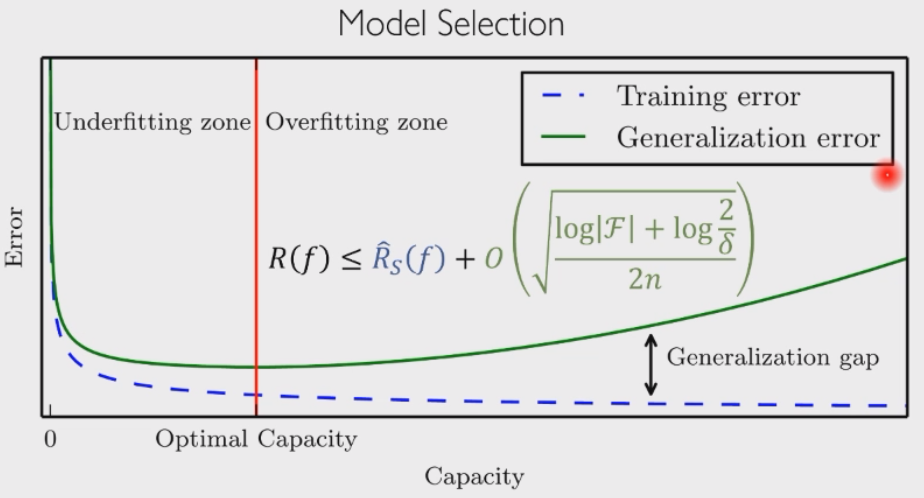
模型选择
所有的模型都是错的,但有些是有用的。
课程定位
掌握深度学习知识,可以做开发和研究。
- 机器学习基础
- 多层感知机
- 卷积神经网络
- 优化方法
- 循环神经网络
- 注意力机制
- 图神经网络
- 生成模型
- 迁移学习
- 应用
- 前沿知识
参考资料
参考书
- Machine Learning, 2012
- Deep Learning, 2016,http://www.deeplearningbook.org/
- Dive Into Deep Learning, 2018,https://zh.d2l.ai/
顶级会议
- 理论:COLT
- 方法:ICML,NIPS,ICLR
- 应用:CVPR,ICCV,ACL,KDD,SIGIR,WWW
顶级期刊
- 方法:JMLR,MLJ
- 应用:TPAMI,AIJ,TKDE,TIP
其他
- 机器学习暑期学校:http://mlss.cc/,有很多丰富的材料